Examples of Sequence Data
- speech recognition
- music generation
- sentiment classification
- DNA sequence analysis
- machine translation
- video activity recognition
- name entity recognition
Recurrent Neural Networks
- Why not a standard network?
- inputs and outputs can be different lengths in different examples, e.g. sentence as input
- does not share features learned across different positions of text
Forward Propagation
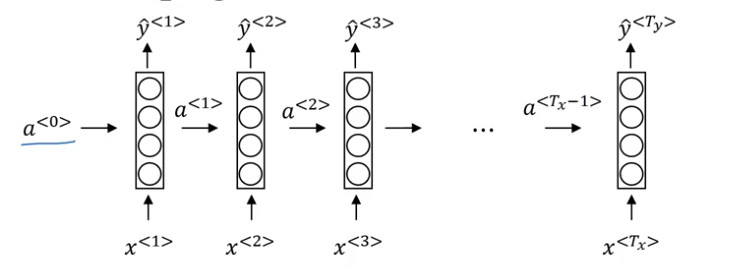
- at time
$t$:
$$
a^{t} = g(W_{aa}a^{t-1} + W_{ax}x^{t} + b_a)\\
\hat{y}^{t}=g(W_{ya}a^{t}+b_y)
$$
- simplified notation:
$$ a^{t} = g(W_a[a^{t-1},x^{t}] + b_a), \text{where} $$
$$ \begin{cases} W_a =[W_{aa}, W_{ax}]\newline [a^{t-1},x^{t}] =\begin{pmatrix} a^{t-1}\newline x^{t} \end{pmatrix} \end{cases}\tag{1} $$
$$ \hat{y}^{t}=g(W_ya^{t}+b_y)\tag{2} $$
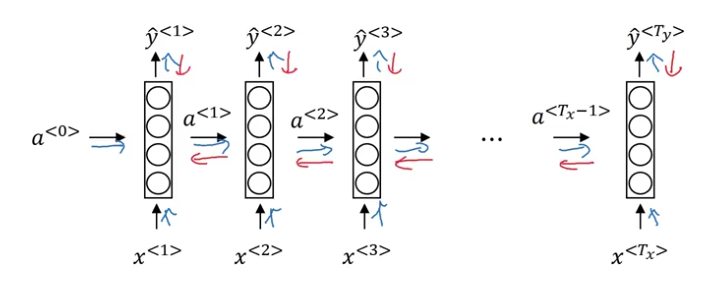
Back Propagation Through Time
- logistic loss:
$$ \mathcal{L}^t(\hat{y}^t,y^{t})=-y^t\log \hat{y}^t-(1-y^t)\log(1-\hat{y}^t) $$
- overall loss:
$$ \mathcal{L}(\hat{y},y)=\sum_{t=1}^{T_y}\mathcal{L}^t(\hat{y}^t,y^{t})\tag{3} $$
Derivative of softmax loss: $$ p = sofmax(z),\ \ \mathcal{L}=-\sum_{k=1}^Ky_k\log p_k $$
$$ \begin{aligned} \frac{\partial p_k}{\partial z_k}&=\frac{\partial}{\partial z_k}\frac{e^{z_k}}{\sum_j e^{z_j}}\newline &=\frac{e^{z_k}}{\sum_j e^{z_j}}-\left(\frac{e^{z_k}}{\sum_j e^{z_j}}\right)^2=p_k(1-p_k), \end{aligned} $$
$$ \begin{aligned} \forall j\neq k, \frac{\partial p_j}{\partial z_k}&=\frac{\partial}{\partial z_k}\frac{e^{z_j}}{\sum_j e^{z_j}}\newline &=-\frac{e^{z_ke^{z_j}}}{(\sum_j e^{z_j})^2}=-p_kp_j \end{aligned} $$
$$ \begin{aligned} \Rightarrow \frac{\partial\mathcal{L}}{\partial{z_k}}&=-\frac{y_k}{p_k}\frac{\partial p_k}{\partial z_k}-\sum_{j\neq k}\frac{y_j}{p_j}\frac{\partial p_j}{\partial z_k}\newline &=-y_k(1-p_k)+\sum_{j\neq k}y_jp_k\newline &=-y_k(1-p_k)+p_k(1-y_k)=p_k-y_k, \end{aligned} $$
$$ \Rightarrow\frac{\partial \mathcal{L}}{\partial z}=p-y $$
backpropagation: single training example
$\mathcal{L}(t):=\mathcal{L}^t(\hat{y}^t,y^{t})$$\forall t<T_x, \frac{\partial J}{\partial a^t}=\frac{\partial a^{t+1}}{\partial a^t}\frac{\partial J}{\partial a^{t+1}}+\frac{\partial \mathcal{L}(t)}{\partial a^t}$$$ \begin{aligned} \frac{\partial J}{\partial a^t}&= \sum_{u\geq t}\frac{\partial\mathcal{L}(u)}{\partial a^t}\newline &=\sum_{u\geq t+1}\frac{\partial\mathcal{L}(u)}{\partial a^t}+\frac{\partial\mathcal{L}(t)}{\partial a^t}\newline &=\sum_{u\geq t+1}\frac{\partial a^{ t+1 }}{\partial a^{ t }}\frac{\partial\mathcal{L}(u)}{\partial a^{t+1}} +\frac{\partial\mathcal{L}(t)}{\partial a^{ t }}\newline &=\frac{\partial a^{ t+1 }}{\partial a^{ t }}\frac{\partial J}{\partial a^{t+1}} +\frac{\partial\mathcal{L}(t)}{\partial a^{t}} \end{aligned} $$
$\frac{\partial a^{ t+1 }}{\partial a^{ t }}\frac{\partial J}{\partial a^{t+1}}=?$$$ z^{t+1}:=W_{aa}a^t + W_{ax}x^{t+1}+b_a, $$
$$ \begin{aligned} \frac{\partial a^{ t+1 }}{\partial a^{ t }}\frac{\partial J}{\partial a^{t+1}} &=\frac{\partial z^{t+1}}{\partial a^t}\frac{\partial a^{ t+1 }}{\partial z^{ t+1 }}\frac{\partial J}{\partial a^{t+1}}\newline &=W_{aa}^T diag\{\tanh’(z^{t+1})_1,\ldots,\tanh’(z^{t+1})_{n_a}\} \frac{\partial J}{\partial a^{t+1}}\newline &=W_{aa}^T\left(tanh’(z^{t+1})* \frac{\partial J}{\partial a^{t+1}}\right)\newline &\text{ (* stands for element-wise multiplication)} \end{aligned} $$
$\frac{\partial J}{\partial W_{aa}}=?$$$ \begin{aligned} \frac{\partial J}{\partial W_{aa}(i,j)}&=\sum_{t=0}^{T_x-1}\frac{\partial J}{\partial a^{t+1}_i} \frac{\partial a^{t+1}_i}{\partial z^{t+1}_i} \frac{\partial z^{t+1}_i}{\partial W_{aa}(i,j)}\newline &= \sum_{t=0}^{T_x-1}\frac{\partial J}{\partial a^{t+1}_i} \tanh’(z^{t+1}_i) a^t_j \end{aligned} $$
$$ \Rightarrow \frac{\partial J}{\partial W_{aa}}=\sum_{t=0}^{T_x-1}\left(tanh’(z^{t+1})* \frac{\partial J}{\partial a^{t+1}}\right)(a^t)^T $$
Similarly, $$ \frac{\partial J}{\partial x^{t+1}}=W_{ax}^T\left(tanh’(z^{t+1})* \frac{\partial J}{\partial a^{t+1}}\right) $$
$$ \frac{\partial J}{\partial W_{ax}}=\sum_{t=0}^{T_x-1}\left(tanh’(z^{t+1})* \frac{\partial J}{\partial a^{t+1}}\right)(x^{t+1})^T $$
$\frac{\partial J}{\partial b_a}=?$$$ \begin{aligned} \frac{\partial J}{\partial b_a}&=\sum_{t=0}^{T_x-1}\frac{\partial z^{t+1}}{\partial b_a} \frac{\partial a^{t+1}}{\partial z^{t+1}} \frac{\partial J}{\partial a^{t+1}}\newline &=\sum_{t=0}^{T_x-1}\mathbf{1}_{n_a}^T diag\{\tanh’(z^{t+1})_1,\ldots,\tanh’(z^{t+1})_{n_a}\} \frac{\partial J}{\partial a^{t+1}}\newline &=\sum_{t=0}^{T_x-1}\mathbf{1}_{n_a}^T \left(tanh’(z^{t+1})* \frac{\partial J}{\partial a^{t+1}}\right) \end{aligned} $$
RNN Step by Step - Python Code
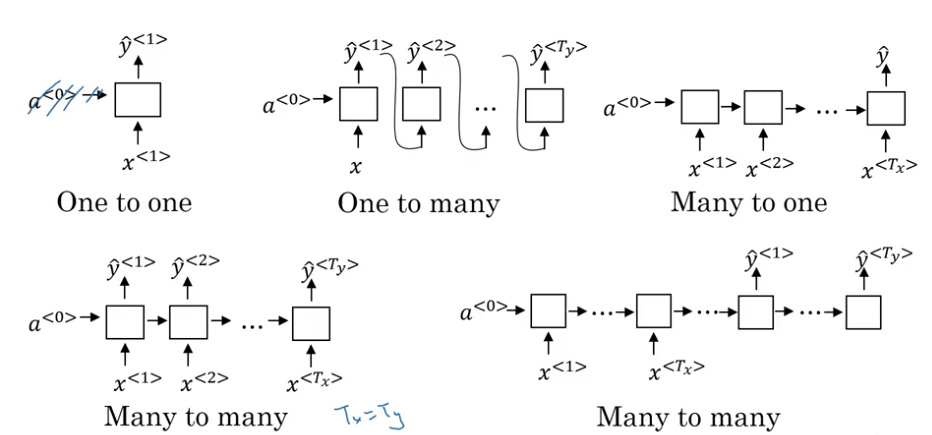
Different Types of RNNs
$T_x=T_y$: many-to-many$1< T_x\neq T_y >1$: many-to-many- e.g. machine translation
$T_y=1$: many-to-one- e.g. sentiment classification
$T_x=1$: one-to-many- e.g. music generation,
$x=$genre
- e.g. music generation,
Language Model and Sequence Generation
- input sentence:
$$ y^1,y^2,\ldots,y^{T_y} $$
- language model: to estimate
$$ \Pr(y^1,y^2,\ldots,y^{T_y}) $$
- training set: large corpus of English text
- tokenize: e.g. map each word to one-hot representation
- add <EOS> (end of sentence token)
- replace word not in the vocabulary with <UNK> (unknown word token)
- build RNN model
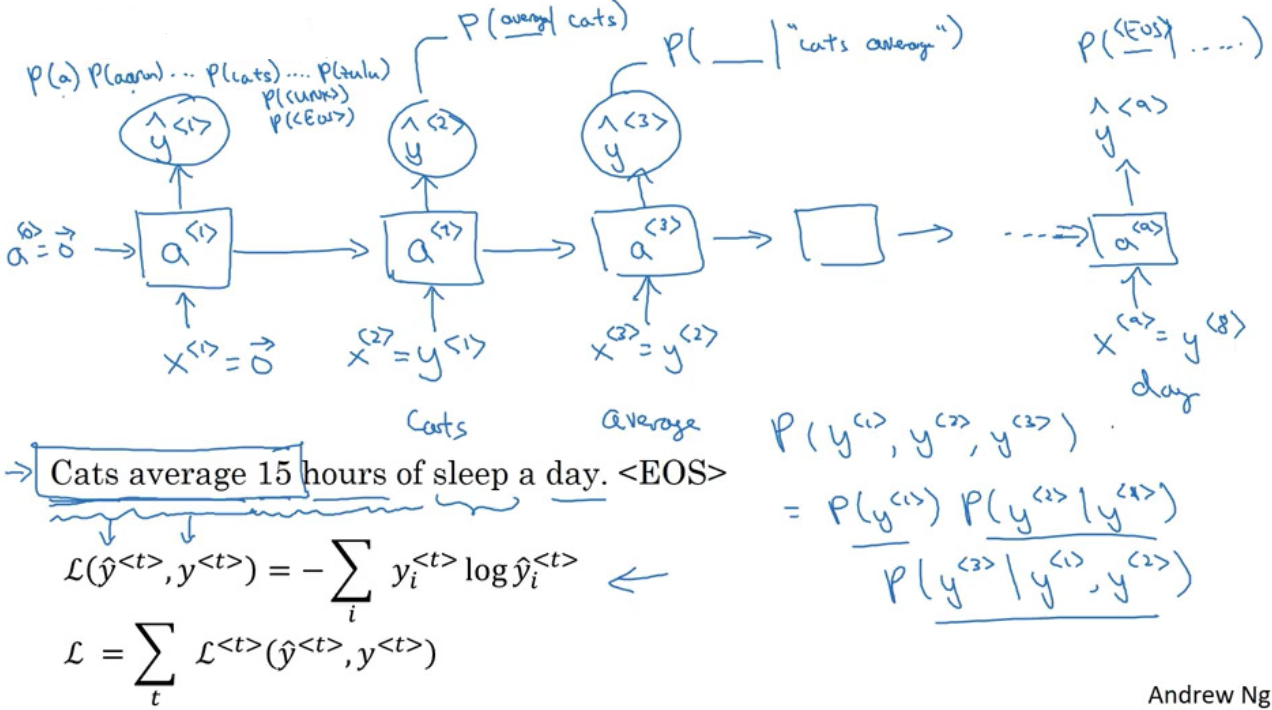
Sampling Novel Sequences
- given input, sampling according to the predicted softmax distribution
np.random.choice- use the previous sampled output as latter input
- keep sampling until <EOS> token is generated, or decide the max sentence length beforehand
Character Level Language Model - Python Code
Vanishing Gradients
- language can have long-term dependency
deep RNN, difficult for the gradients of output to propagate back to affect the weights of earlier layers
$\Rightarrow$vanishing gradient problem
solve exploding gradients: gradient clipping
- if gradients exceed some threshold, rescale gradients
solve vanishing gradients?
Gated Recurrent Unit (GRU)
- captures long range connections
- helps with vanishing gradient problems
- simplified GRU unit: memory cell
$c^t = a^t$(need$c^t$to be highly dependent on$c^{t-1}$)
$$
\tilde{c}^t=\tanh(W_c[c^{t-1},x^t]+b_c),\\
\Gamma_u=\sigma(W_u[c^{t-1},x^t]+b_u),\ \ \text{u for ‘update’, decide when to update } c^t\\
c^t = \Gamma_u * \tilde{c}^t +(1-\Gamma_u) *c^{t-1},\ \ \text{element-wise multiplication}
$$
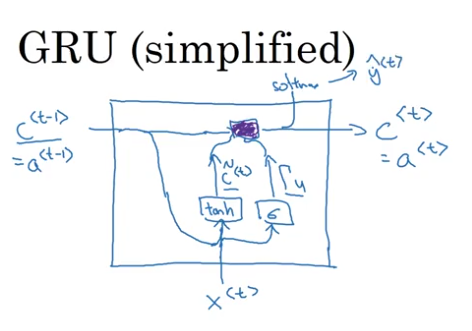
- full GRU unit: (simplified:
$\Gamma_r=1$)
$$
\tilde{c}^t=\tanh(W_c[\Gamma_r *c^{t-1},x^t]+b_c),\ \ \text{‘r’ for ‘relevant’}\\
\Gamma_u=\sigma(W_u[c^{t-1},x^t]+b_u),\\
\Gamma_r=\sigma(W_r[c^{t-1},x^t]+b_r),\\
c^t = \Gamma_u * \tilde{c}^t +(1-\Gamma_u) *c^{t-1}
$$
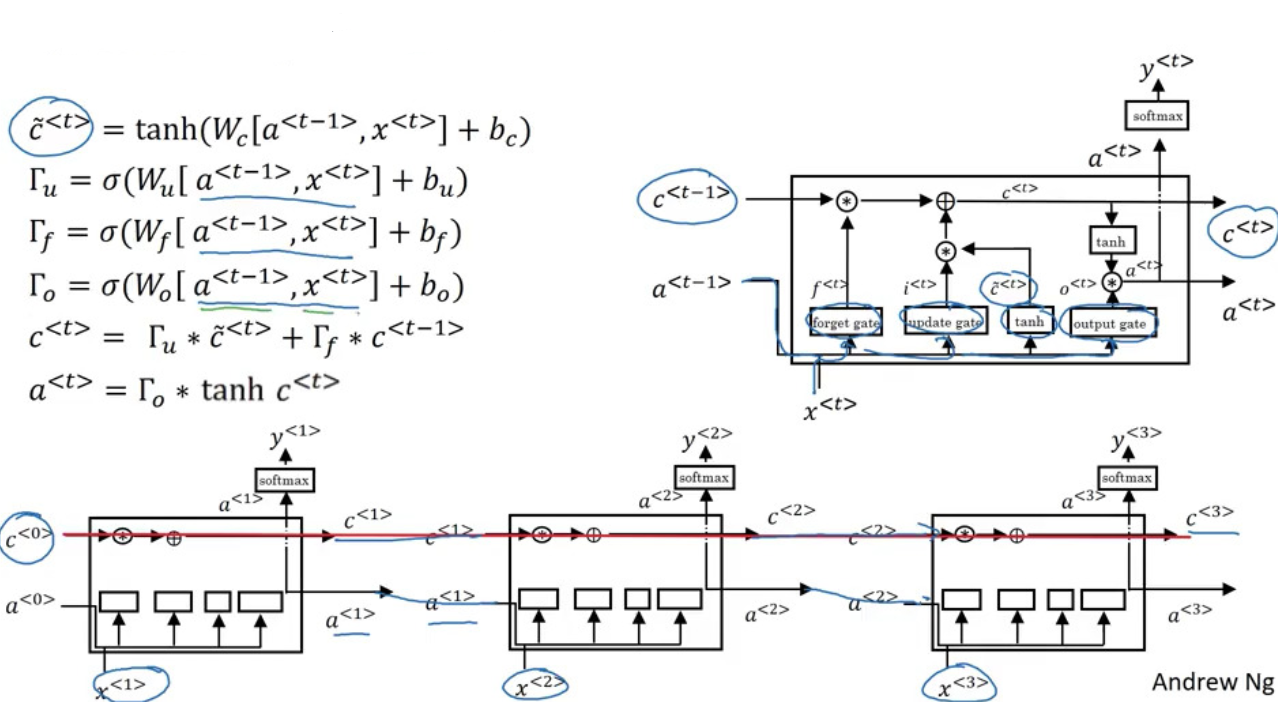
Long Short Term Memory (LSTM)
- u, f, o = update, forget, output
- GRU: simpler, can build deep model
$\Gamma_u, 1-\Gamma_u$play the same role as$\Gamma_u, \Gamma_f$
- LSTM: more powerful
LSTM Step by Step - Python Code
Text Generation: Writing Like Shakespeare - Python Code
Bidirectional RNNs (BRNN)
- motivation: gain information from the future
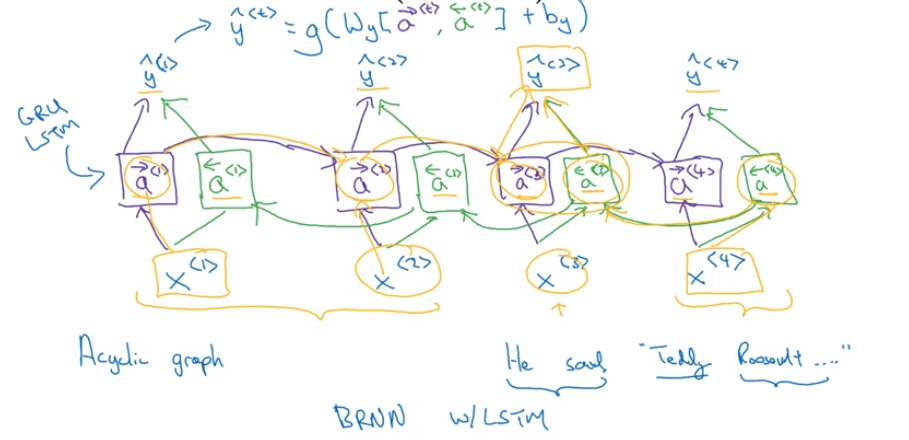
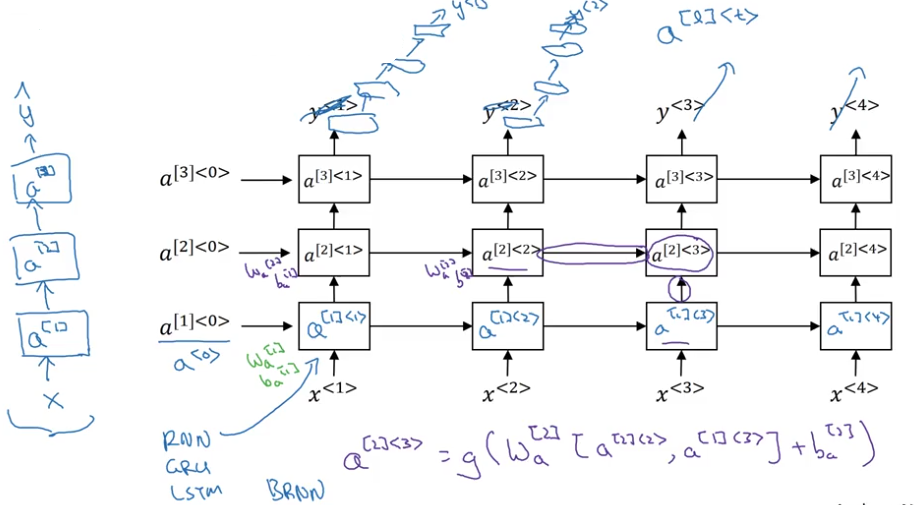
Deep RNNs
For layer $\ell$,
$$
a^{[\ell]t}=g(W_a^{[\ell]}[a^{[\ell]t-1}, a^{[\ell-1]t}] +b_a^{[\ell]})
$$
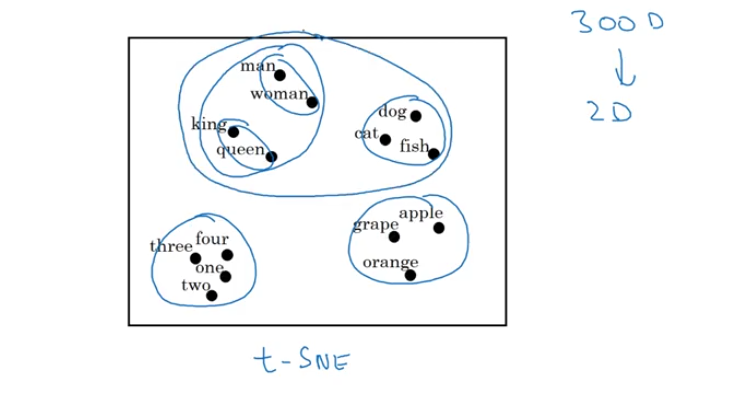
NLP and Word Embedding
Word Representation
- one-hot representation
- featurized representation: word embedding

- t-SNE: visualizing word embeddings
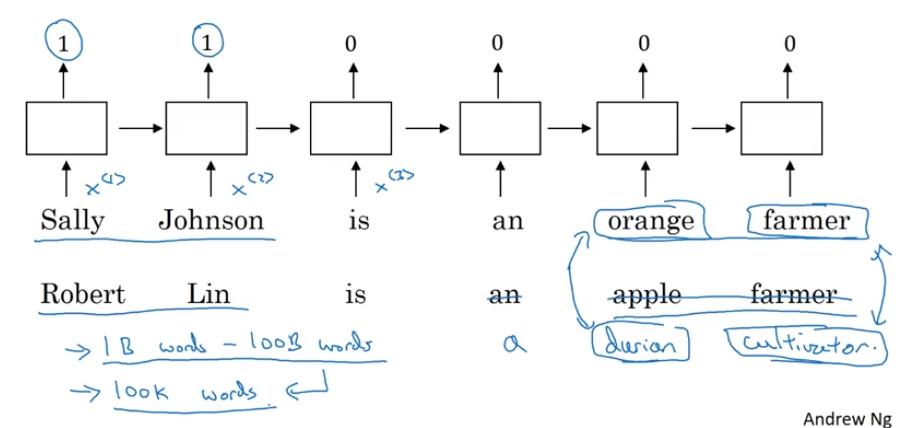
Using Word Embeddings
- name entity recognition
- transfer learning
- learn word embeddings from large text corpus (1-100b words) (or download pre-trained embedding online)
- transfer embedding to new task with smaller training set (say, 100k words)
- optional: continue to fine-tune the word embeddings with new data
- BRNN
- relation to face encoding
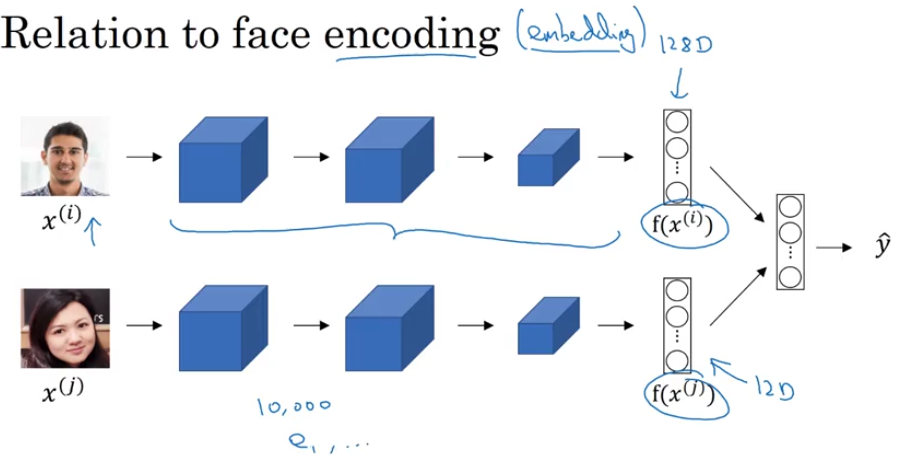
Properties of Word Embeddings
- analogies: man:woman is king:?
- find word
$w$:
$$ \arg\max_w sim(e_w, e_{king}-e_{man}+e_{woman}) $$

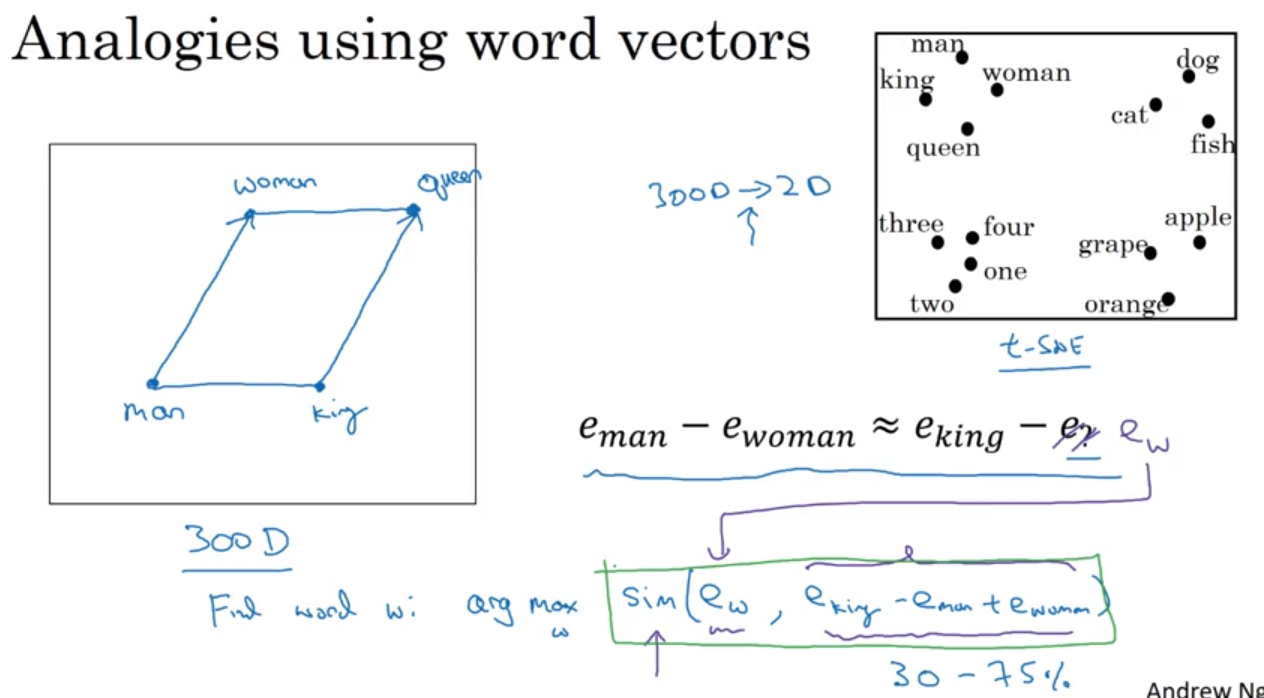
- similarity function:
- cosine similarity (most common)
$$ sim(u,v)=\frac{u^Tv}{\Vert u\Vert_2 \Vert v\Vert_2} $$
Embedding Matrix
- embedding matrix
$E$ - embedding for word
$w$:$e_w$ - one-hot representation for word
$w$:$O_w$
$$ EO_w = e_w $$
- in practice, not efficient to use matrix multiplication to look up an embedding
Learning Word Embeddings
- neural language model
- fixed history
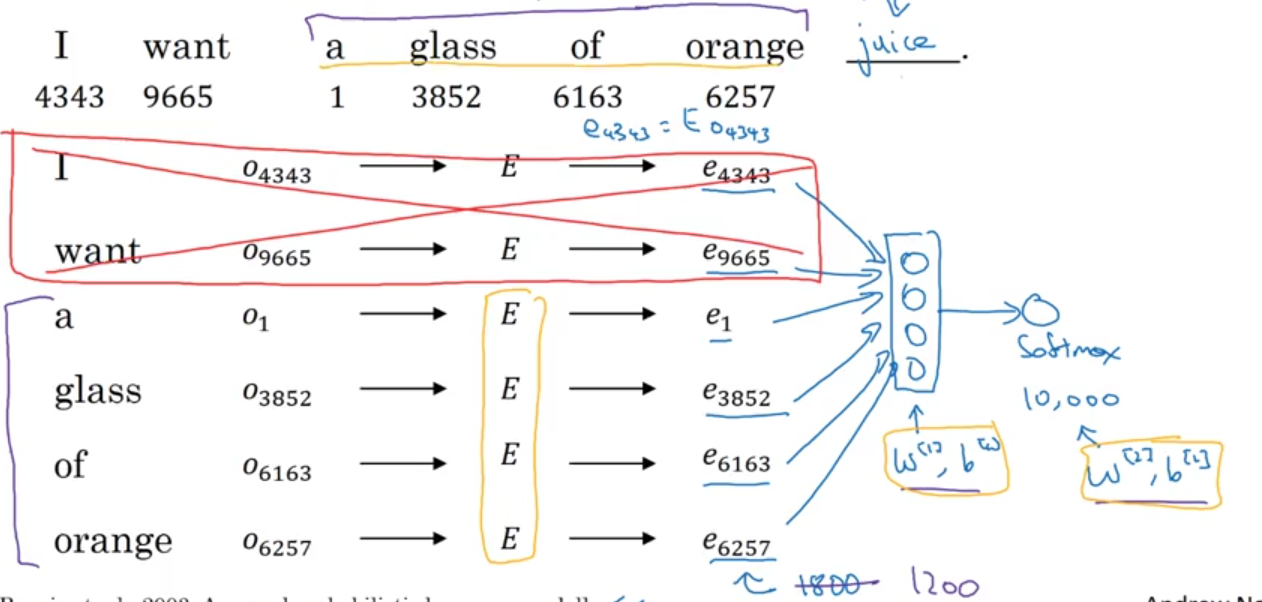
- context/target pairs
$\rightarrow$context- goal: build language model
- last 4 words
- goal: learn embedding
- 4 words on left & right
- last 1 word
- nearby 1 word
- goal: build language model
Word2Vec
- skip-grams
- randomly pick a word to be the context word
- randomly pick another word within some window to be the target word
- supervised model
- vocab size
$= v$- context
$c\rightarrow$target$t$$$ O_c\rightarrow E\rightarrow e_c\rightarrow softmax\rightarrow \hat{y} $$
$$ softmax: \Pr(t|c)=\frac{e^{\theta_t^Te_c}}{\sum_{j=1}^{v}e^{\theta_j^Te_c}} $$
- loss:
$$ \mathcal{L}(\hat{y},y)=-\sum_{i=1}^{v}y_i\log\hat{y}_i $$
- problems: computationally expensive to compute
$\Pr(t|c)$ - solutions:
- hierarchical softmax:
- tree of binary classifiers
- cost:
$O(\log v)$better than$O(v)$(softmax classifier) - build unbalanced tree: common words on the top
- negative sampling
- hierarchical softmax:
- how to sample context
$c$?- not uniform sampling: the, of, a, …
Negative Sampling
- pick a context word
- generate a positive example:
- for the context word, look around a window
- generate
$K$negative examples:- for the context word, randomly pick a word
- supervised learning problem
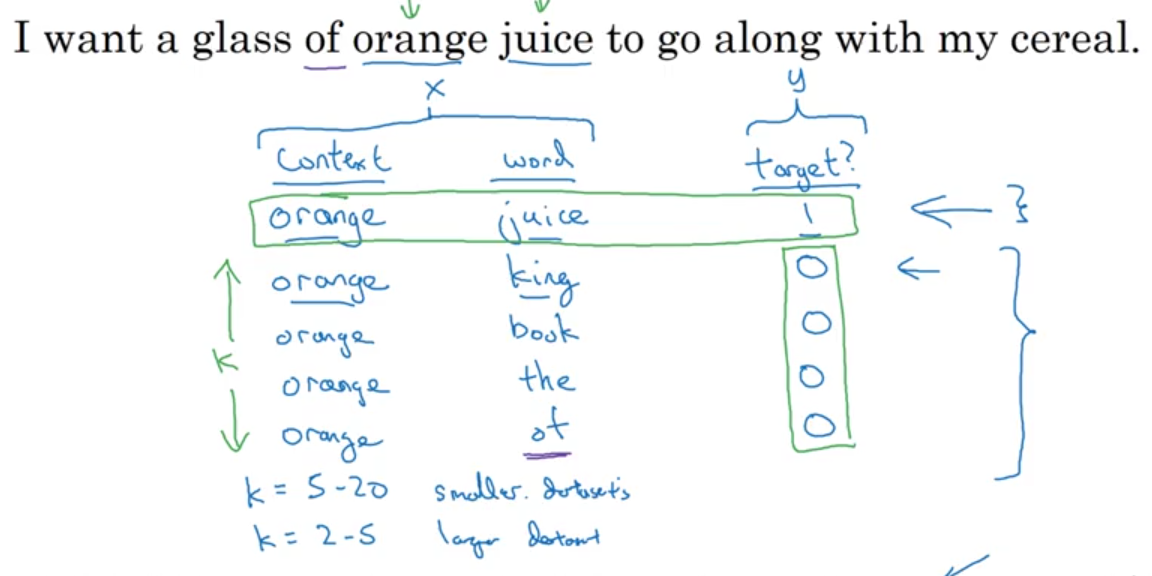
- logistic regression model:
$$ \Pr(y=1|c,t)=\sigma(\theta_t^Te_c) $$
- instead of a large softmax model, train
$v$logistic models - how to sample random target words?
- heuristic: between uniform distribution and empirical distribution
$$ \Pr(w_i)=\frac{f(w_i)^{0.75}}{\sum_jf(w_j)^{0.75}}, \ \ f(w_i) = \text{ frequency of word }w_i $$
GloVe
- Global Vectors for Word Representation
$$ X_{ct} = \text{# of times word }c \text{ appears in context of word }t = X_{tc} $$
- model: minimize
$$ \sum_{c,t=1}^v f(X_{ct})(\theta_c^Te_t+b_c+b’_t-\log X_{ct})^2, \text{where weighting term} $$
$$ f(X_{ct})=0 \text{ for } X_{ct}=0 \text{ and gives more weight to uncommon words} $$
- since
$\theta_c,e_t$are symmetric
$$ e_w^{(final)}:=\frac{\theta_w+e_w}{2} $$
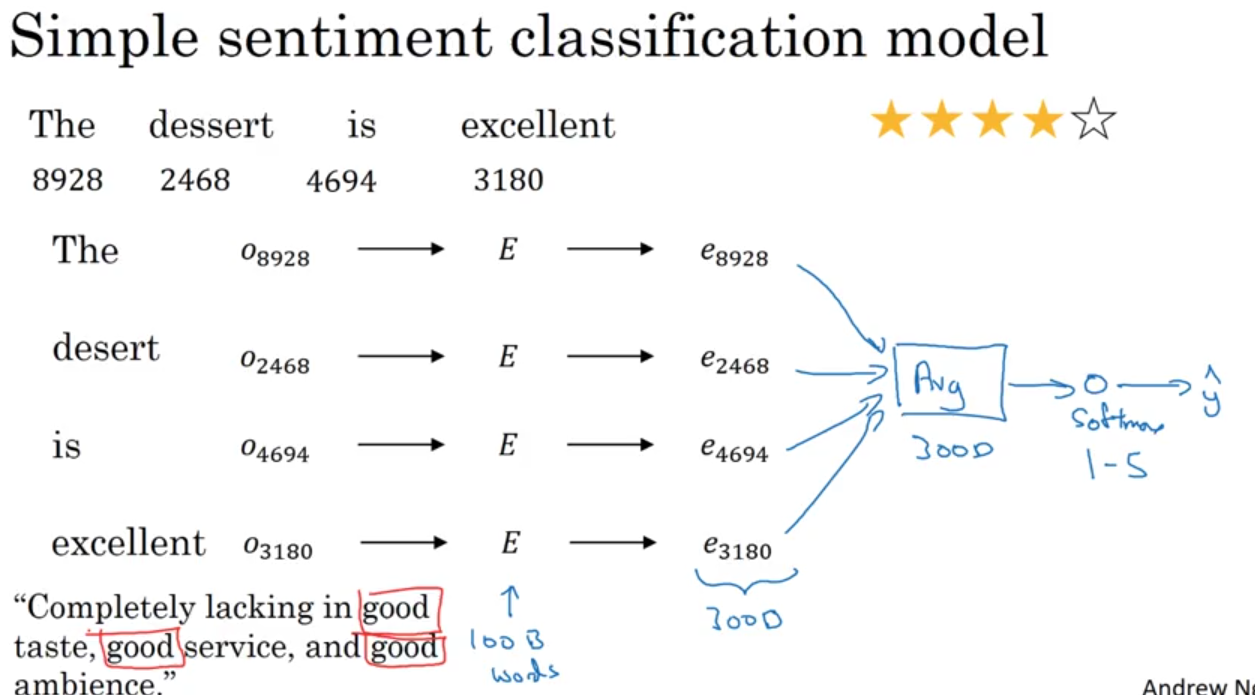
Sentiment Classification
- simple sentiment classification
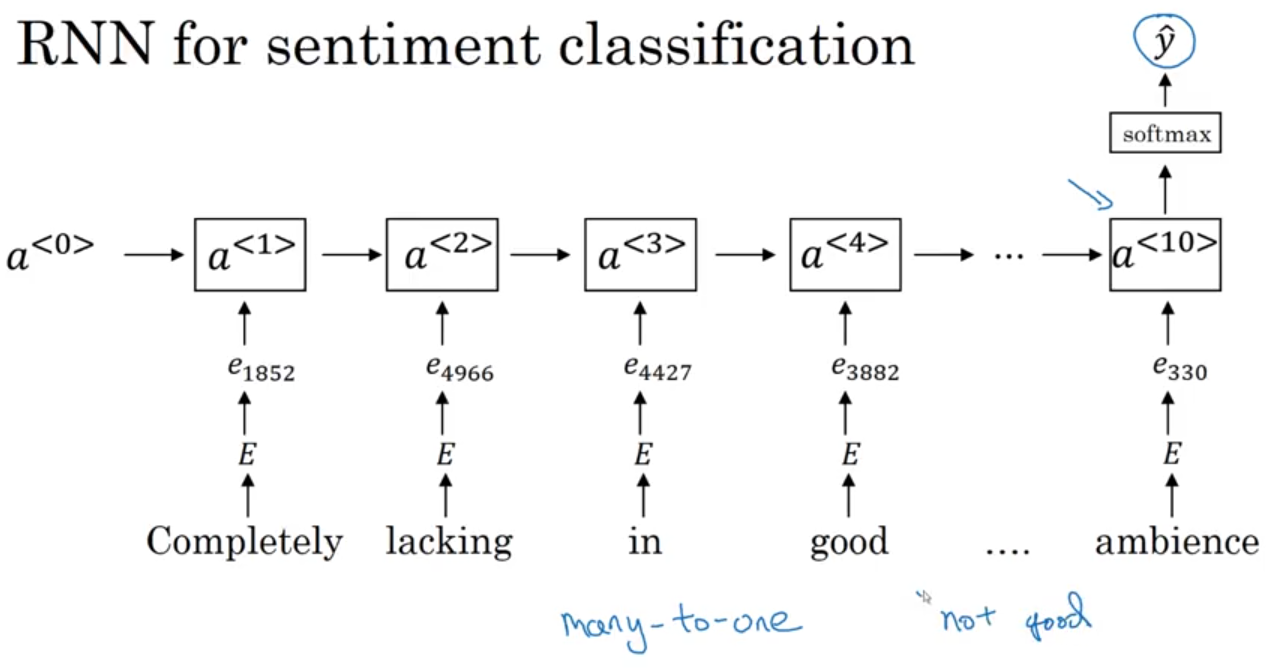
- (many-to-one) RNN for sentiment classification
Debiasing Word Embeddings

Sequence to Sequence Model
- encoder network
- decoder network
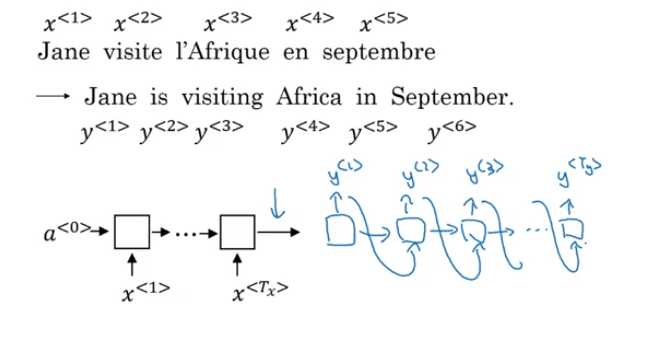
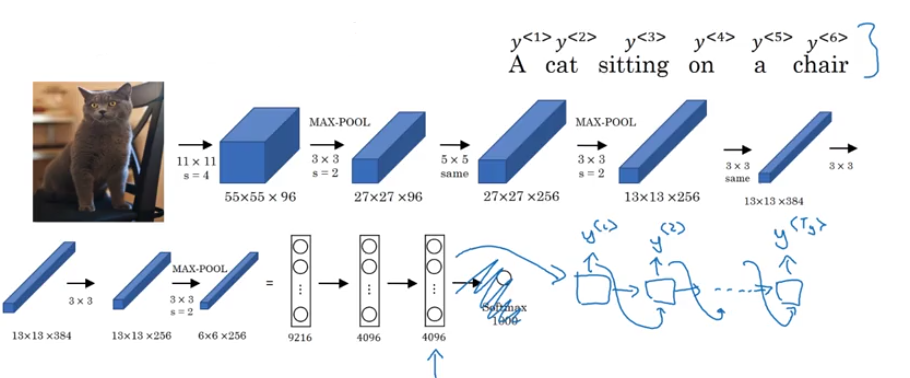
Image Captioning
- use pre-trained cnn
Machine Translation as Building a Conditional Language Model
- language model vs machine translation model
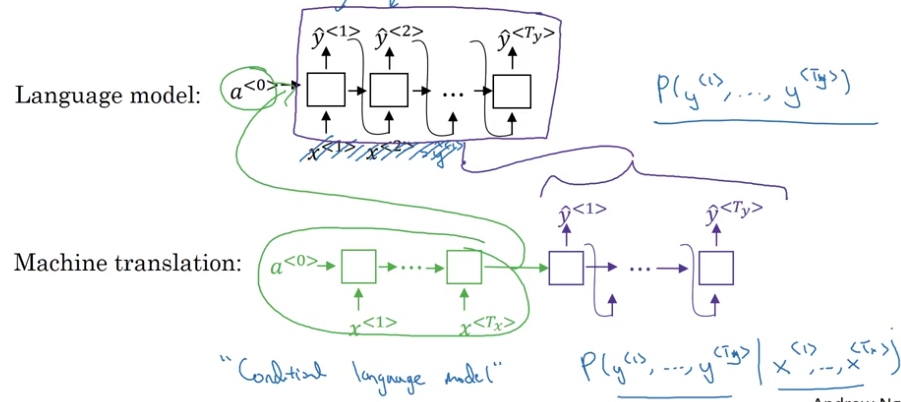
- finding the most likely translation
$$ \arg\max_{y^1,y^2,\ldots,y^{T_y}}\Pr(y^1,\ldots,y^{T_y}|x) $$
- beam search vs greedy search
- greedy search: each time, find the most likely single word
Beam Search
- first word?
$\Pr(y^1|x)$- parameter
$B$: beam width (consider$B$possibilities at one time) $B=1$, greedy search
- parameter
- second word?
$y^1,y^2$with top$B$
$$ \Pr(y^1,y^2|x)=\Pr(y^1|x)\Pr(y^2|y^1,x) $$
Refinements to Beam Search
- BS unnaturally prefers shorter sentences
$$ \arg\max_y\prod_{t=1}^{T_y}\Pr(y^t|x,y^1,\ldots,y^{t-1}) $$
$$ \overset{\text{avoid numerical rounding error}}{\Longrightarrow} \arg\max_y\sum_{t=1}^{T_y}\log\Pr(y^t|x,y^1,\ldots,y^{t-1}) $$
- length normalization
- heuristic:
$\alpha \in (0,1)$
- heuristic:
$$ \frac{1}{T_y^{\alpha}}\arg\max_y\sum_{t=1}^{T_y}\log\Pr(y^t|x,y^1,\ldots,y^{t-1}) $$
- choice of
$B$- large beam width: consider large possibilities, better result, slower
- small beam width: worse result, faster
- unlike exact search algorithms like BFS or DFS, BS runs faster but is not guaranteed to find exact maximum
Error Analysis in Beam Search
- human translation
$y^*$, algorithm output$\hat{y}$ - case 1:
$\Pr(y^*|x)>\Pr(\hat{y}|x)$- BS chose
$\hat{y}$, but$y^*$attains higher$\Pr(y|x)$ - BS is at fault
- BS chose
- case 2:
$\Pr(y^*|x)<\Pr(\hat{y}|x)$$y^*$is a better translation than$\hat{y}$, but RNN predicted$\Pr(y^*|x)<\Pr(\hat{y}|x)$- RNN model is at fault

Bleu Score
- evaluate machine translation
- bleu = bilingual evaluation understudy
$p_n$= Bleu score on n-grams only- combined Bleu score:
$$ BP \exp\left(\frac{1}{K}\sum_{i=1}^K p_K\right) $$
$$ \text{BP penalty (brevity penalty)}:= \begin{cases} 1, &\text{if MT_output_length>reference_output_length}\newline \exp(1-\text{ MT_output_length/reference_output_length}),&\text{otherwise} \end{cases} $$
- download open source implementation



Attention Model Intuition
- problem of long sequences
- BRNN, attention weight
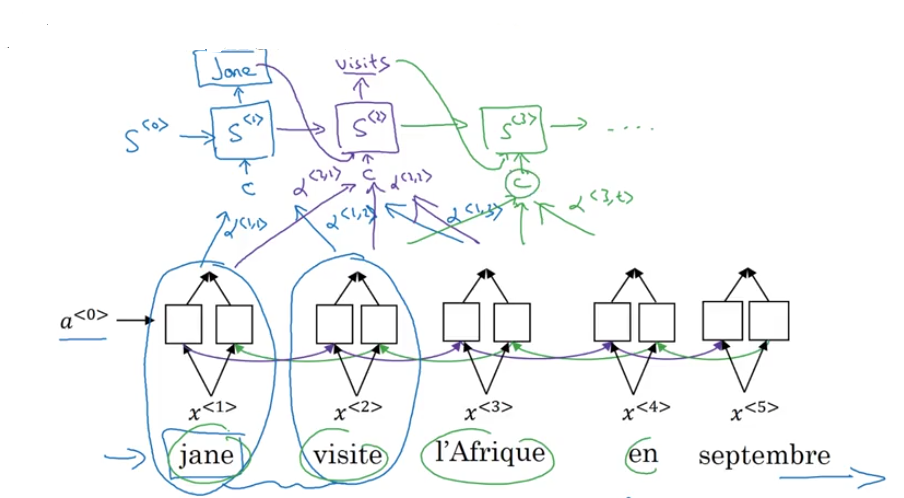
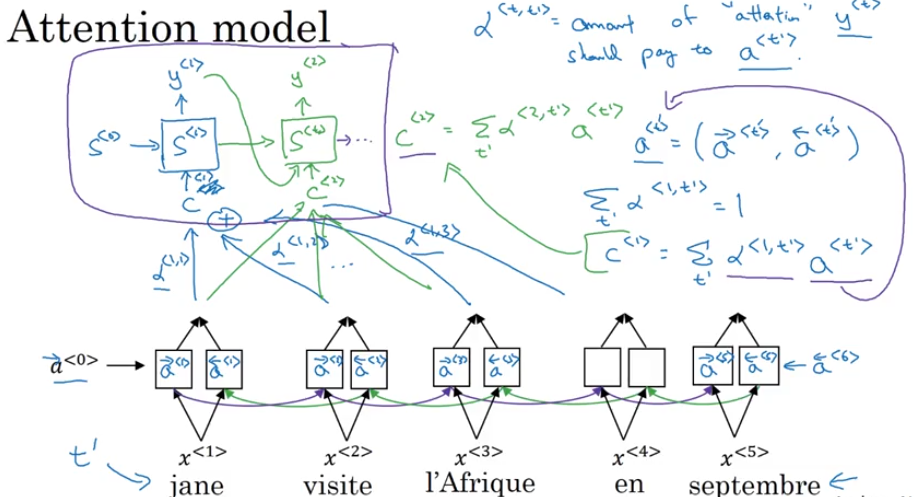
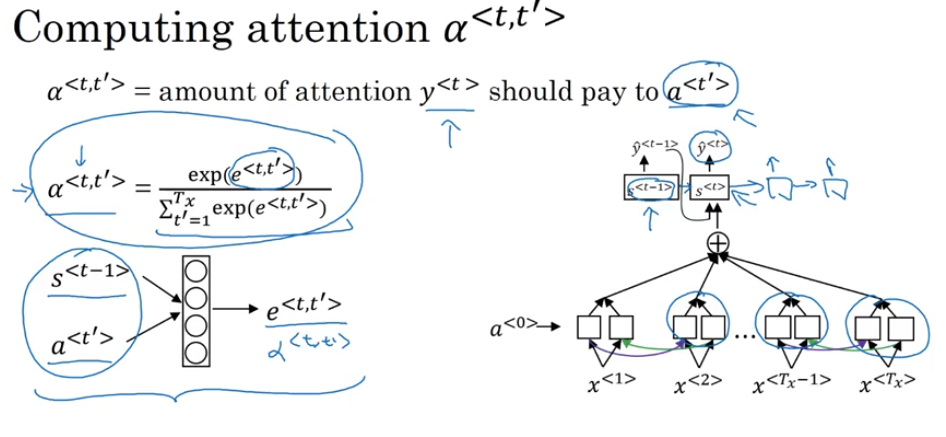
Speech Recognition
attention models
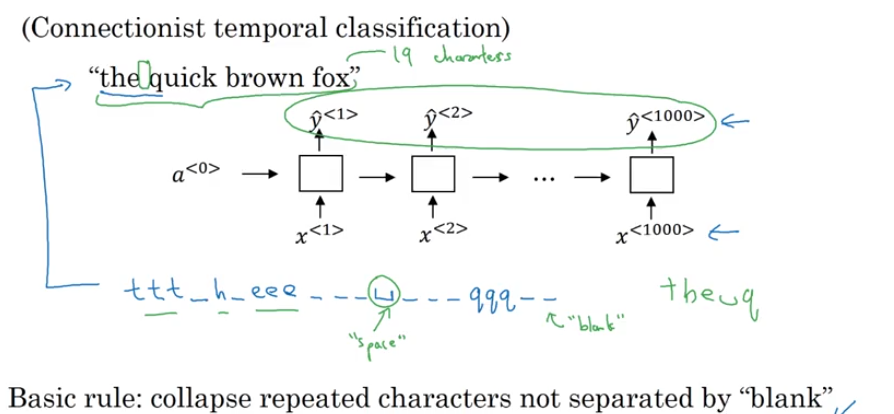
CTC cost (connectionist temporal classification)
- collapse repeated characters note separated by “blank”
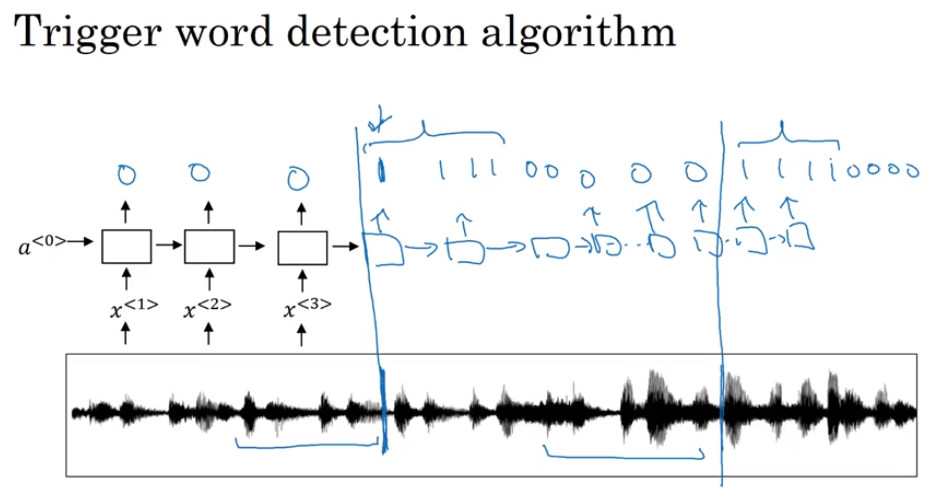
Trigger Word Detection