Building Blocks of CNN
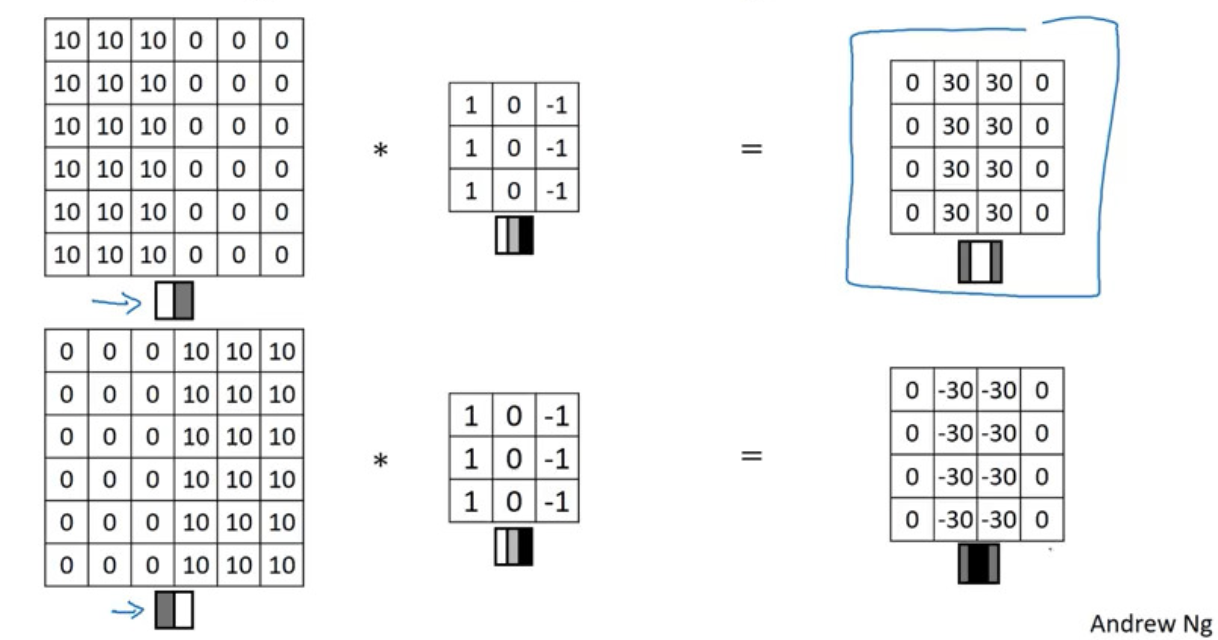
Edge Detection
Vertical Edge Detection
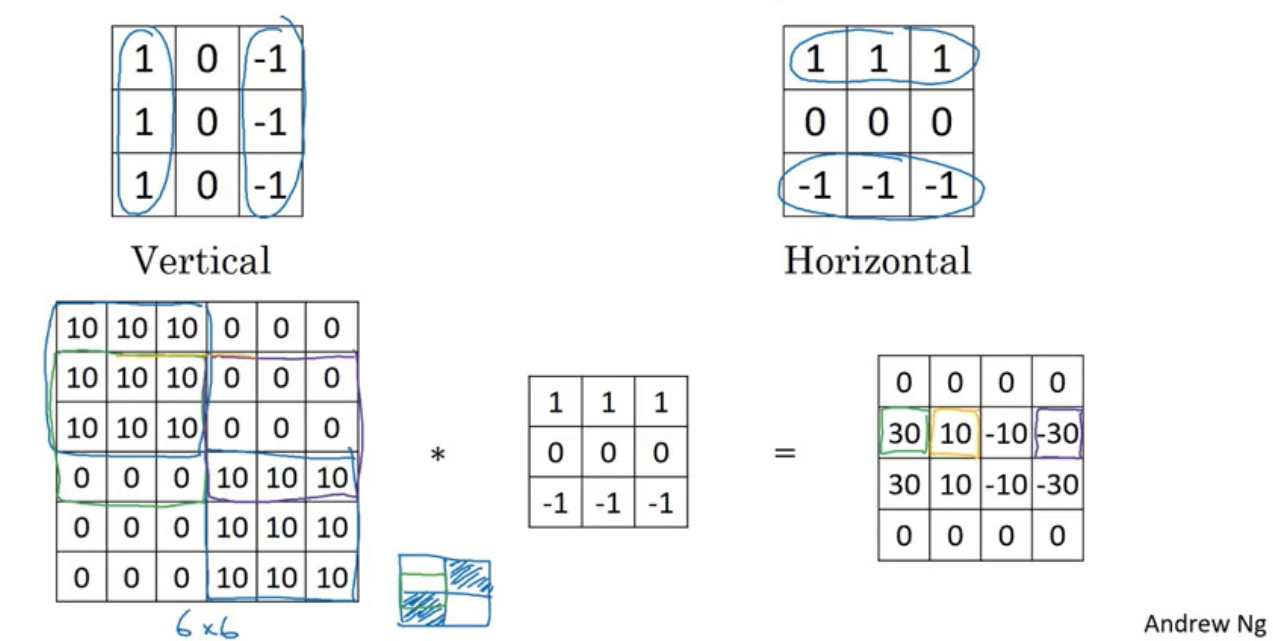
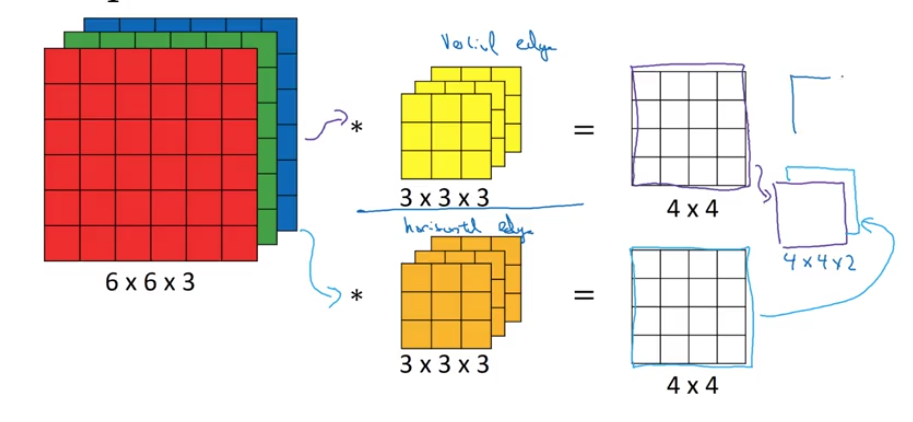
Vertical and Horizontal Edge Detection
Convolution Operation
- tensorflow:
tf.nn.conv2d - keras:
conv2D
Padding
$n\times n$image, convolves with a$f\times f$filter$\Rightarrow (n-f+1)\times(n-f+1)$output- downside:
- shrinking output
- pixels at the corner is touched only once, information from the edge is thrown away
- padding with zeros,
$p=$padding amount - output:
$(n+2p-f+1)\times (n+2p-f+1)$
Valid and Same Convolutions
- valid: no padding
- same: output size = input size,
$2p+1=f$,$f$is usually odd
Strided Convolution
$n\times n$image, convolves with a$f\times f$filter, with padding$p$and stride$s$$\Rightarrow$output size$=\left(\lfloor\frac{n+2p-f+1}{s}\rfloor+ 1\right)\times \left(\lfloor\frac{n+2p-f+1}{s}\rfloor+ 1\right)$
Convolution Over Volume
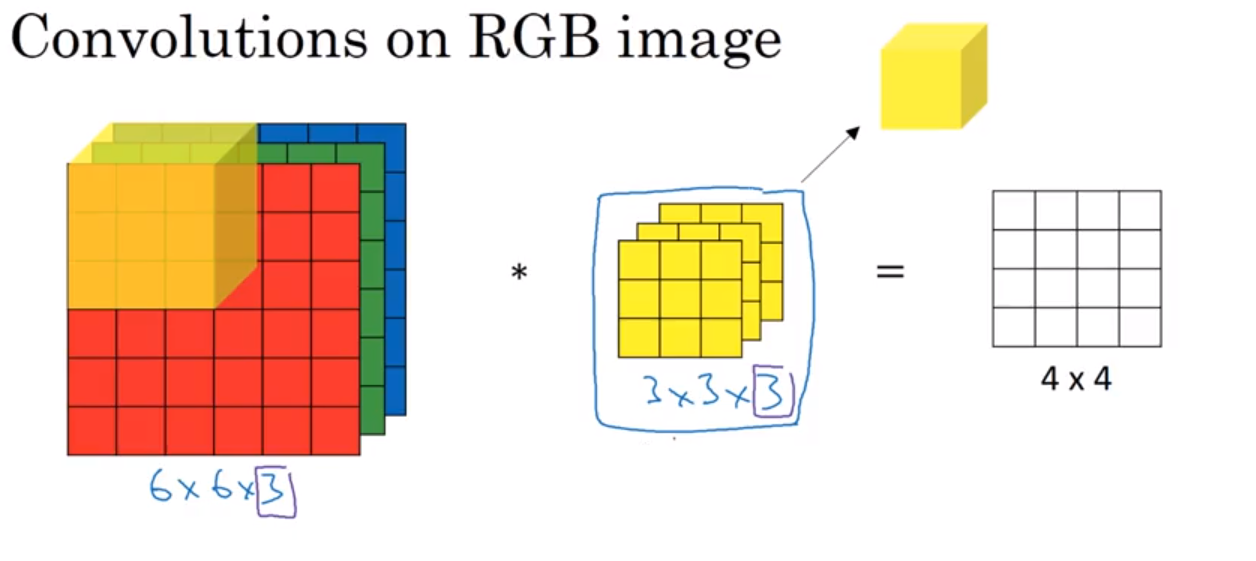
- input size:
$n\times n\times n_C$($n_C = $# of channels) $n_C'$filters, each of size:$f\times f\times n_C$(each has$f\times f\times n_C$parameters)- output size:
$(n-f+1)\times (n-f+1)\times n_C'$
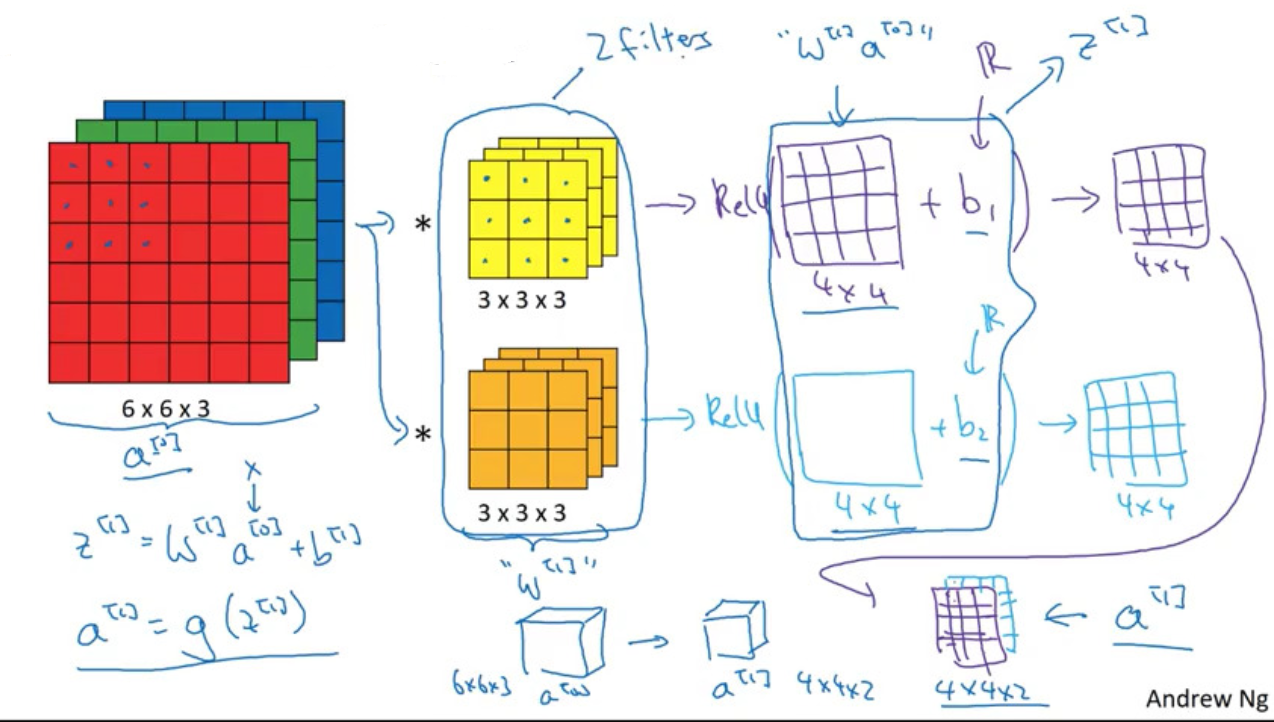
One Layer of a Convolutional Network
- Notations: layer
$\ell$$f^{[\ell]}$= filter size$p^{[\ell]}$= padding$s^{[\ell]}$= stride$n^{[\ell]}_C$= # of filters- input size:
$n^{[\ell-1]}_H\times n^{[\ell-1]}_W\times n^{[\ell-1]}_C$ - each filter size:
$f^{[\ell]}\times f^{[\ell]}\times n^{[\ell-1]}_C$ - output size:
$n^{[\ell]}_H\times n^{[\ell]}_W\times n^{[\ell]}_C$, where $$n^{[\ell]}_H=\left\lfloor \frac{n^{[\ell-1]}_H +2p^{[\ell]}-f^{[\ell]}}{s^{[\ell]}} +1 \right\rfloor,\\
n^{[\ell]}_W=\left\lfloor \frac{n^{[\ell-1]}_W +2p^{[\ell]}-f^{[\ell]}}{s^{[\ell]}} +1 \right\rfloor$$ - activations:
$n^{[\ell]}_H\times n^{[\ell]}_W\times n^{[\ell]}_C$ - weights:
$f^{[\ell]}\times f^{[\ell]}\times n^{[\ell-1]}_C\times n^{[\ell]}_C$ - bias:
$1\times 1\times 1\times n^{[\ell]}_C$
Simple Convolutional Network Example
Types of layer in a convolutional network:
- Convolution (CONV)
- Pooling (POOL)
- Fully connected (FC)

Pooling Layer
- hyperparameters
$f$: filter size$s$: stride- max or average pooling
$p$: padding (rarely use)
- no parameters to learn!
- input size:
$n_H\times n_W\times n_c$ - output size (no padding):
$\lfloor \frac{n_H-f}{s}+1\rfloor \times \lfloor \frac{n_W-f}{s}+1\rfloor\times n_c$
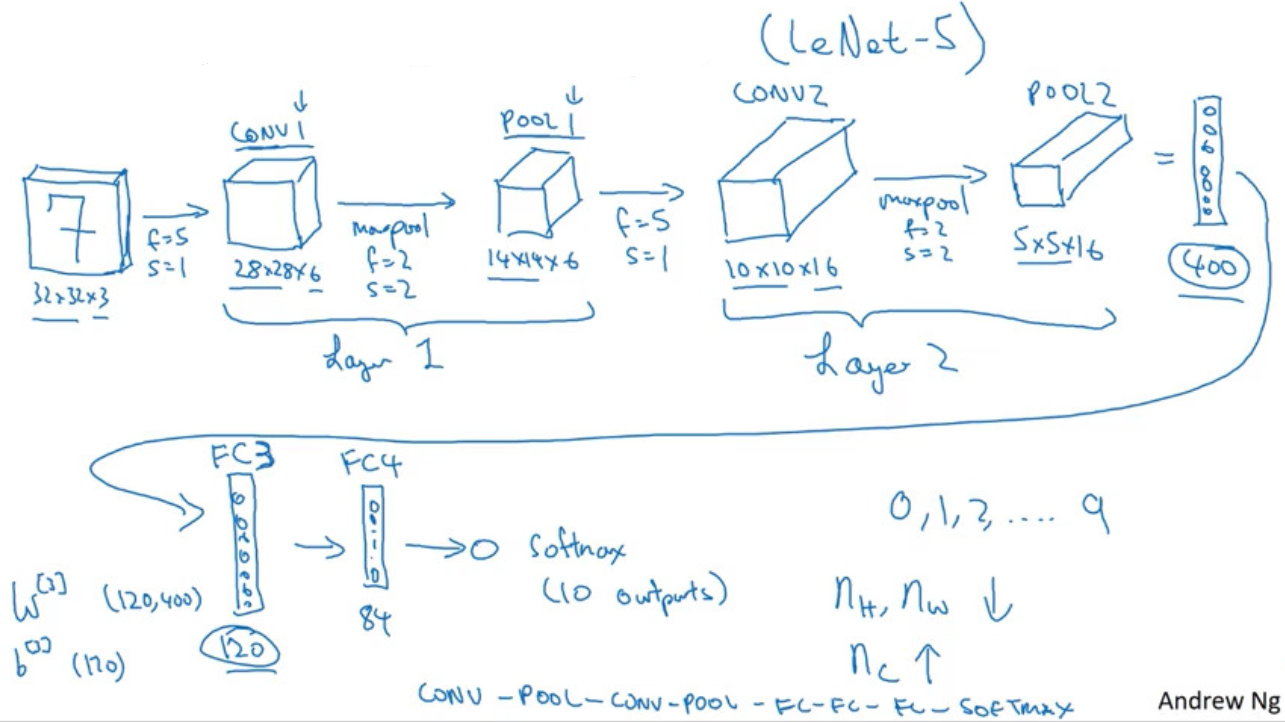
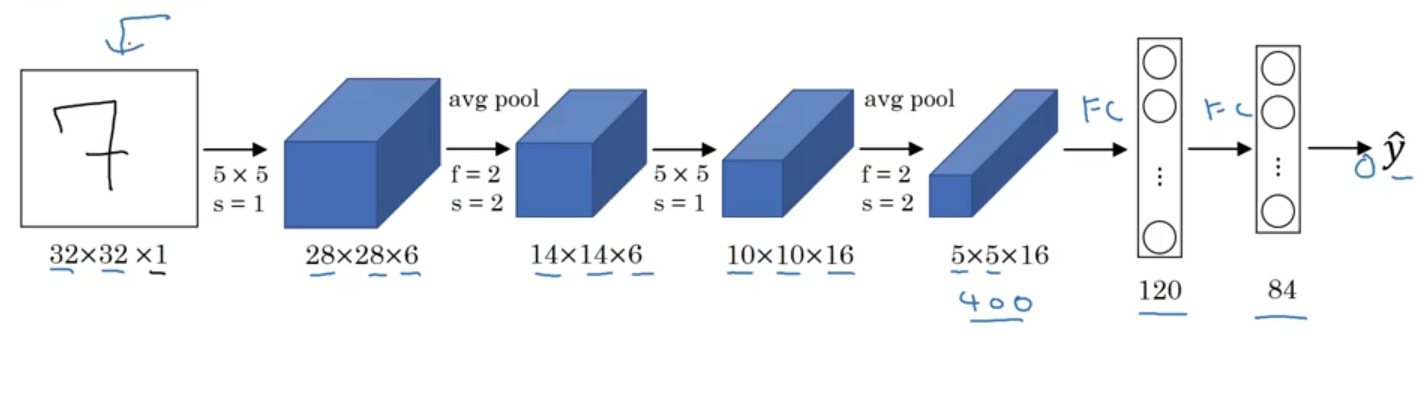
Neural Network Example (Inspired by LeNet-5)
Why Convolutions?
- parameter sharing: a feature detector (such as a vertical edge detector) that is useful in one part of the image is probably useful in another part of the image; reduces the total number of parameters, thus reducing overfitting
- sparsity of connections: in each layer, each output value depends only on a small number of inputs
CNN Step By Step - Python Code
CNN Application-Sign Recognition
Case Studies
Classic Networks
LeNet-5
- structure: CONV - POOL - CONV - POOL - FC - FC - OUTPUT
$n_H, n_W \downarrow$,$n_C\uparrow$- # of parameters: 60k
- advanced:
- not use sigmoid/tanh, use ReLU
- use max pool, not avg pool
- LeNet-5 adds nonlinearity after pooling
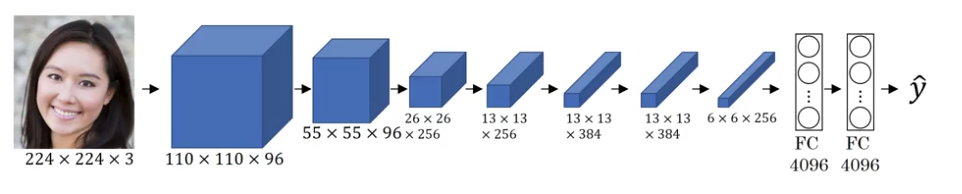
AlexNet
- similar to LeNet, but much bigger, 60m parameters
$$
(11\times 11\times 3+1)\times 96+(5\times 5\times 96+1)\times 256 + (3\times 3\times 256+1)\times 384 \\
+(3\times3\times 384+1)\times 384+ (3\times3\times 384 +1)\times 256 + (9216+1)\times 4096 \\
+(4096+1)\times 4096 + (4096+1)\times 10 =58,322,314
$$
- ReLU activation
- multiple GPUs
- local response normalization (LRN) 【does not help much】
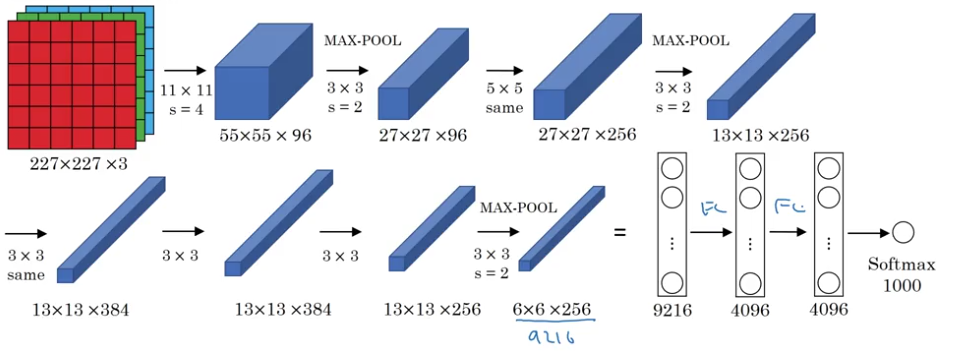
VGG-16
- # of parameters: 138m
- VGG-19, an even bigger version
$n_H, n_W \downarrow$by a factor of 2,$n_C\uparrow$by a factor of 2
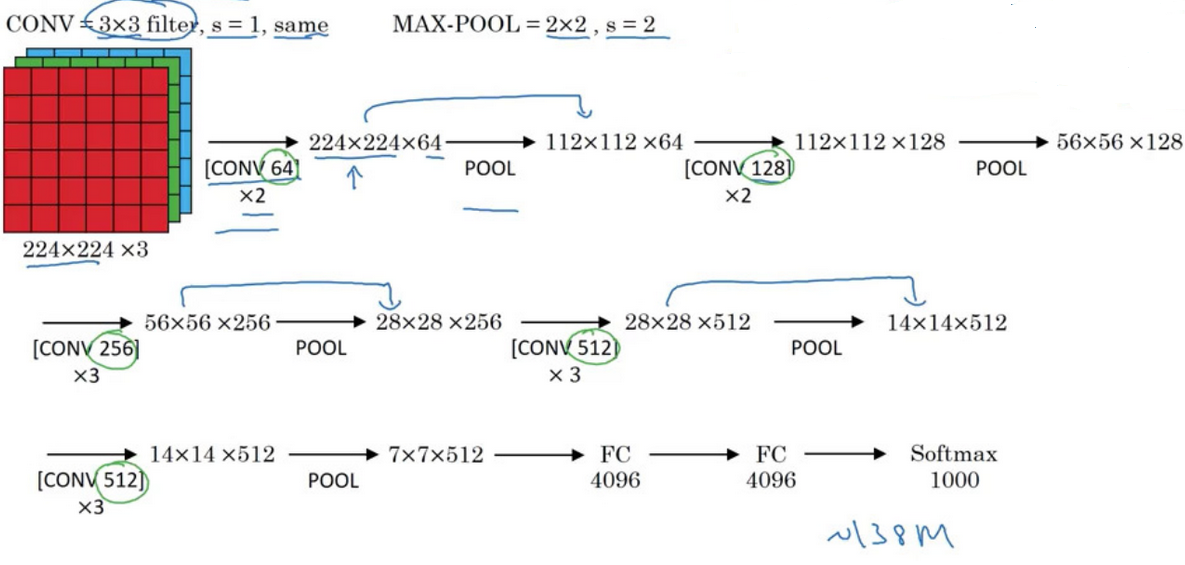
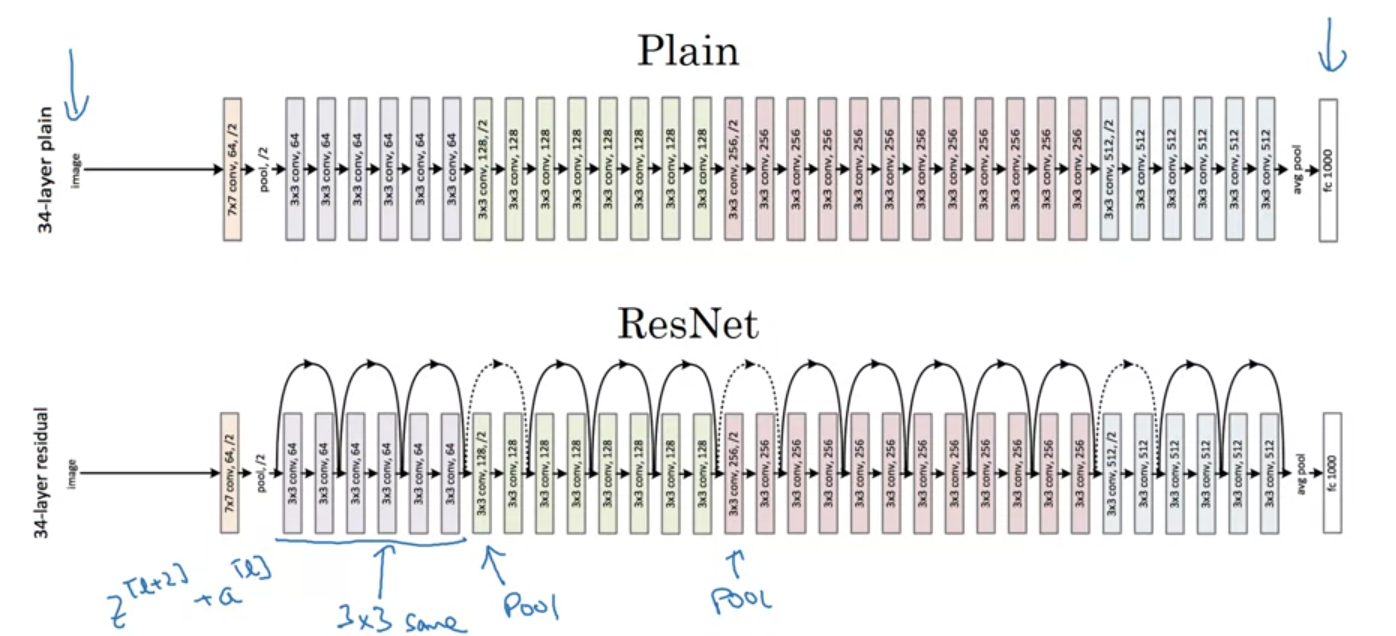
Residual Networks (ResNets)
- very deep neural networks are difficult to train because of vanishing/exploding gradients
- skip connection
Residual Block
- short-cut
$$ a^{[\ell+2]}=g(z^{[\ell +2]}+a^{[\ell]}) $$
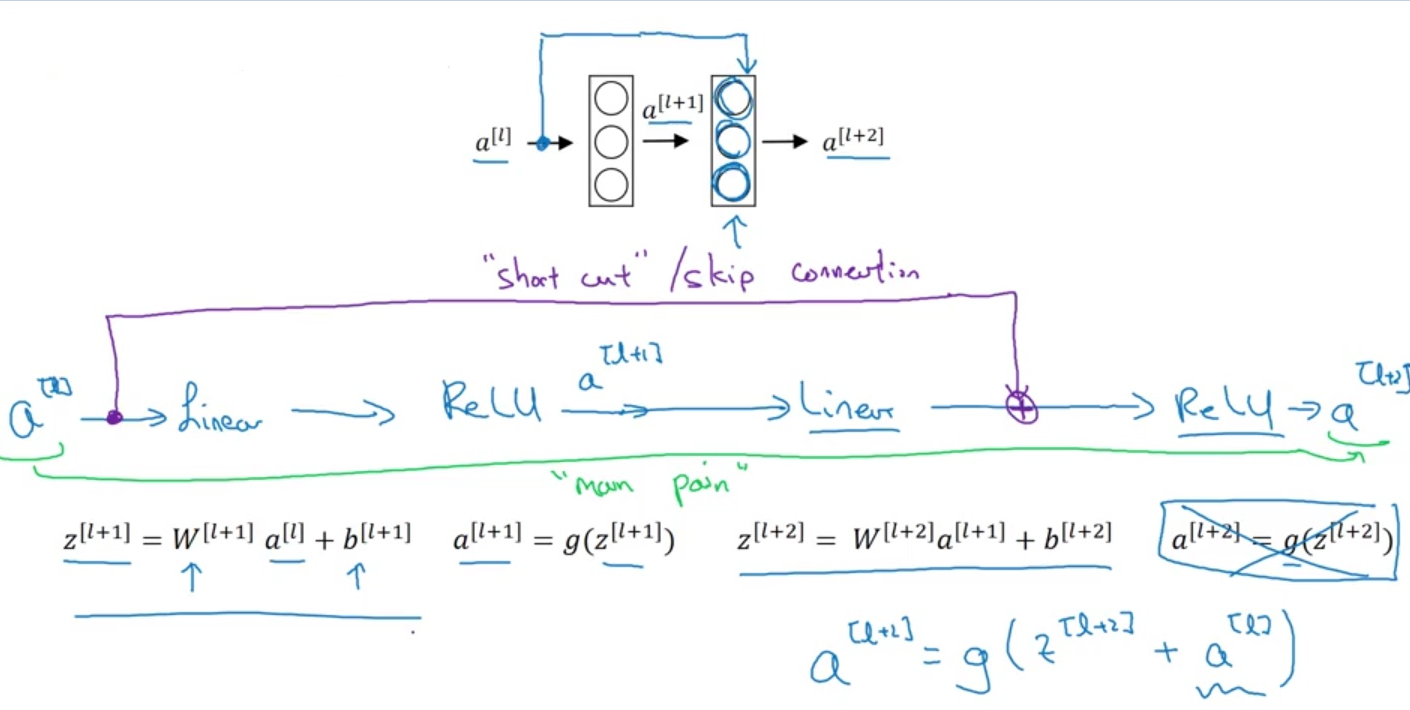
- residual networks: helps to build deep networks
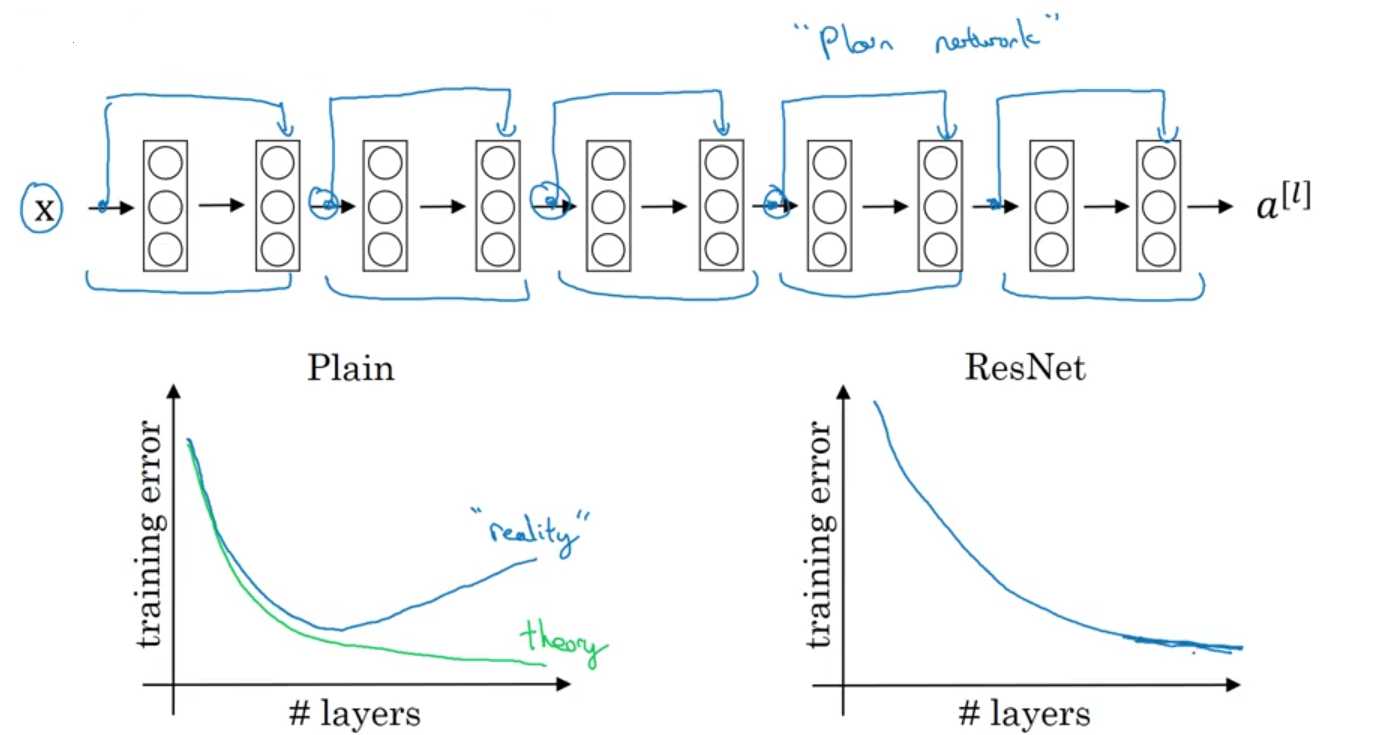
- why resnets work?
- if
$W^{[\ell+2]}=0$,$b^{[\ell+2]}=0$,$g$is ReLU activation,$\Rightarrow a^{[\ell+2]}=a^{[\ell]}$(identity function is easy for resnet to learn)$\Rightarrow$guarantees not to hurt performance $z^{[\ell+2]}$needs to be the same dimension as$a^{[\ell]}$:- use SAME convolution, or
- add extra matrix,
$a^{[\ell+2]}=g(z^{[\ell +2]}+W_s a^{[\ell]})$,$W_s$can be parameters to learn, or zero padding
- if
Signs Recognition with ResNet - Python Code
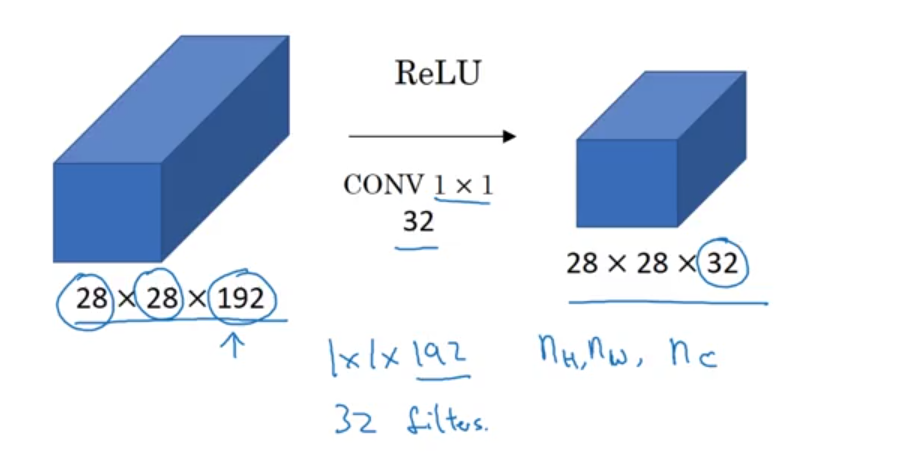
One-By-One Convolution
- pooling: shrinks
$n_H, n_W$ $1\times 1$convolution, aka networks in network- interpretation: a fully-connect neural network applied to each of the
$n_H\times n_W$positions - increases or decreases
$n_C$ - adds nonlinearity
- interpretation: a fully-connect neural network applied to each of the
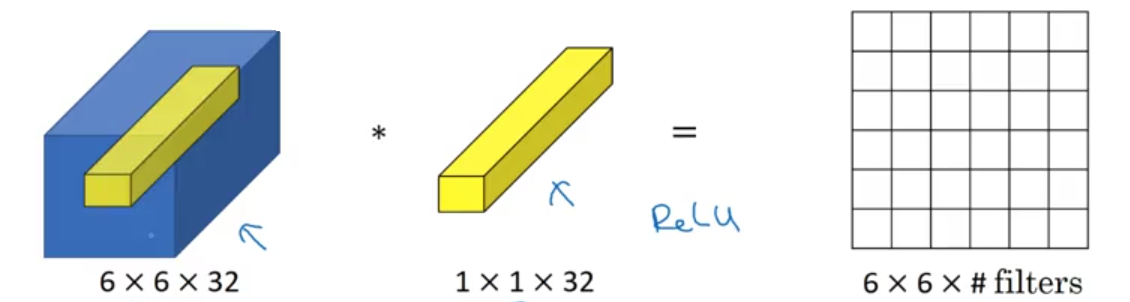
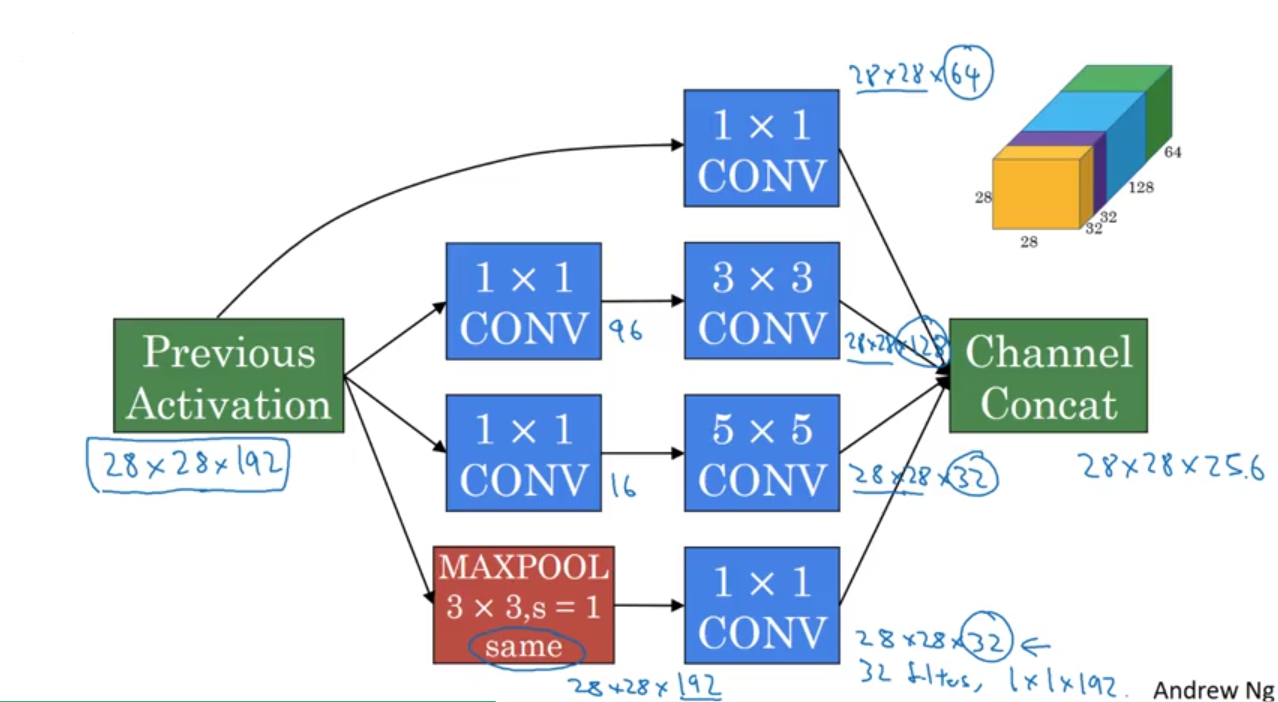
Inception Network
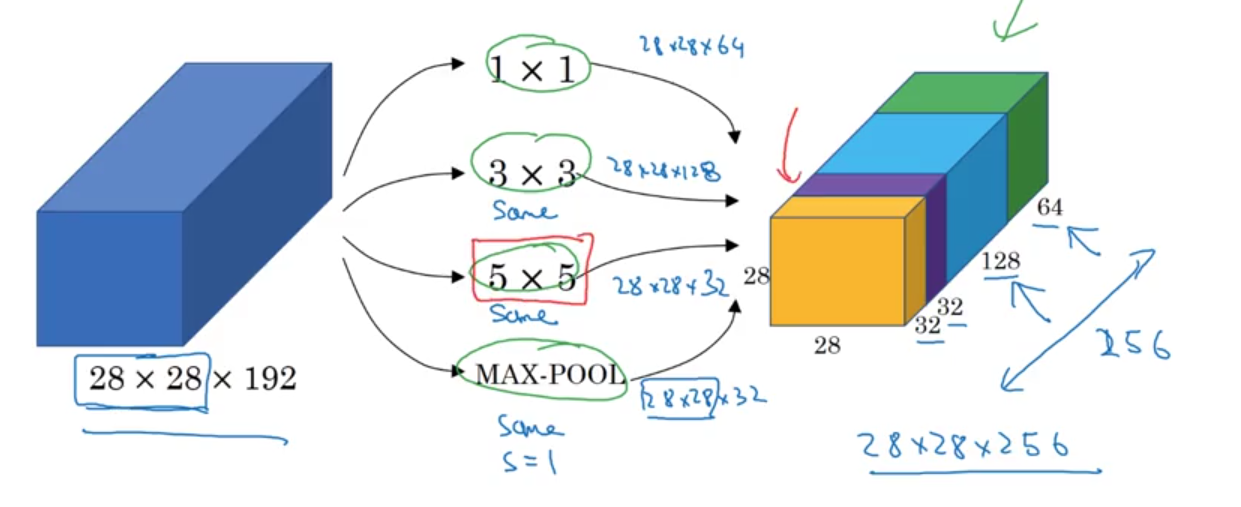
- # of multiplications:
$28\times 28\times 192\times 5\times 5\times 32\approx 120$m
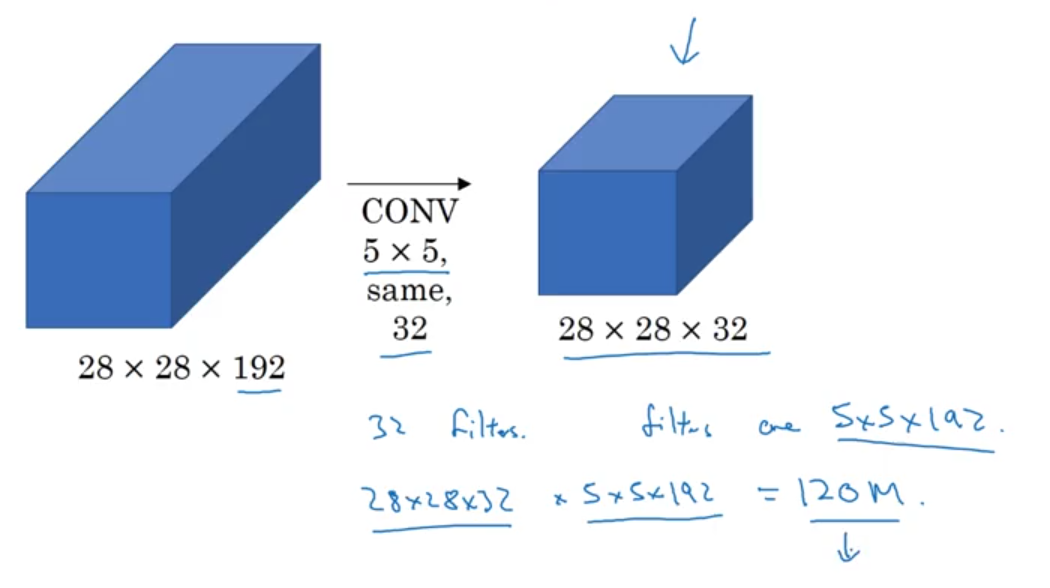
- # of multiplications:
$28\times 28\times 192\times 16 + 28\times28\times16\times5\times5\times 32\approx 12.4$m
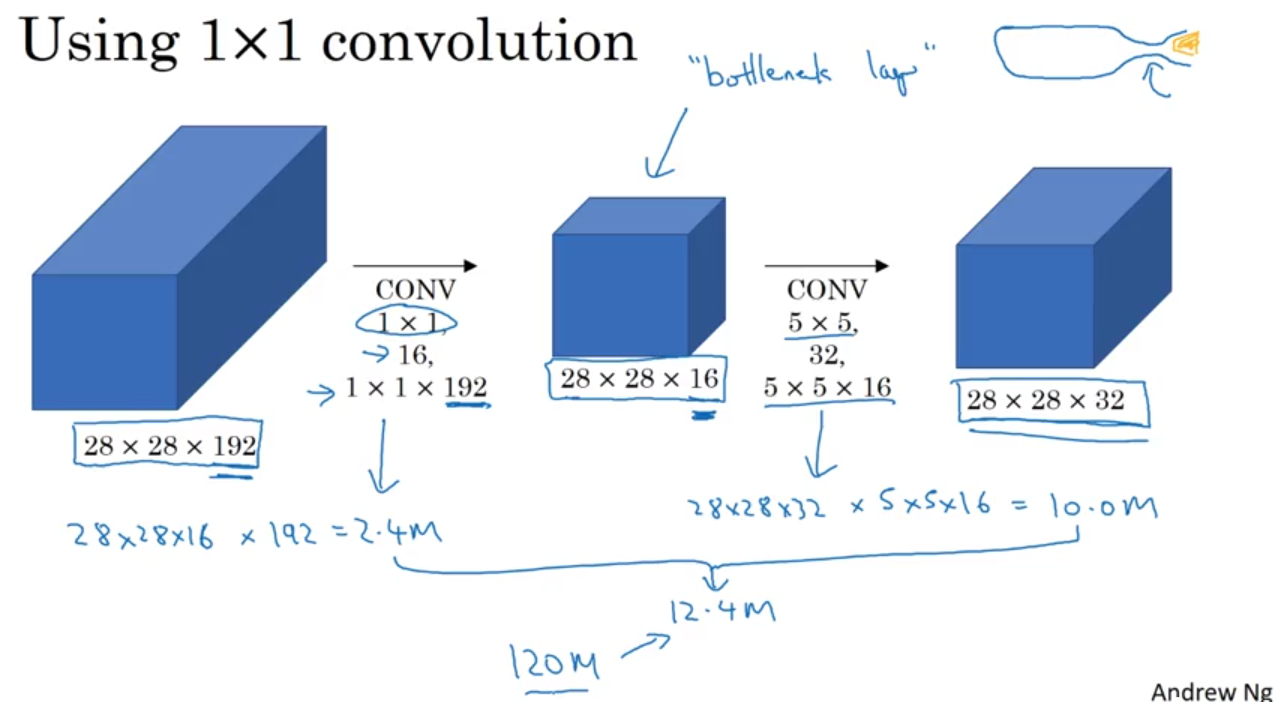
Inception Module
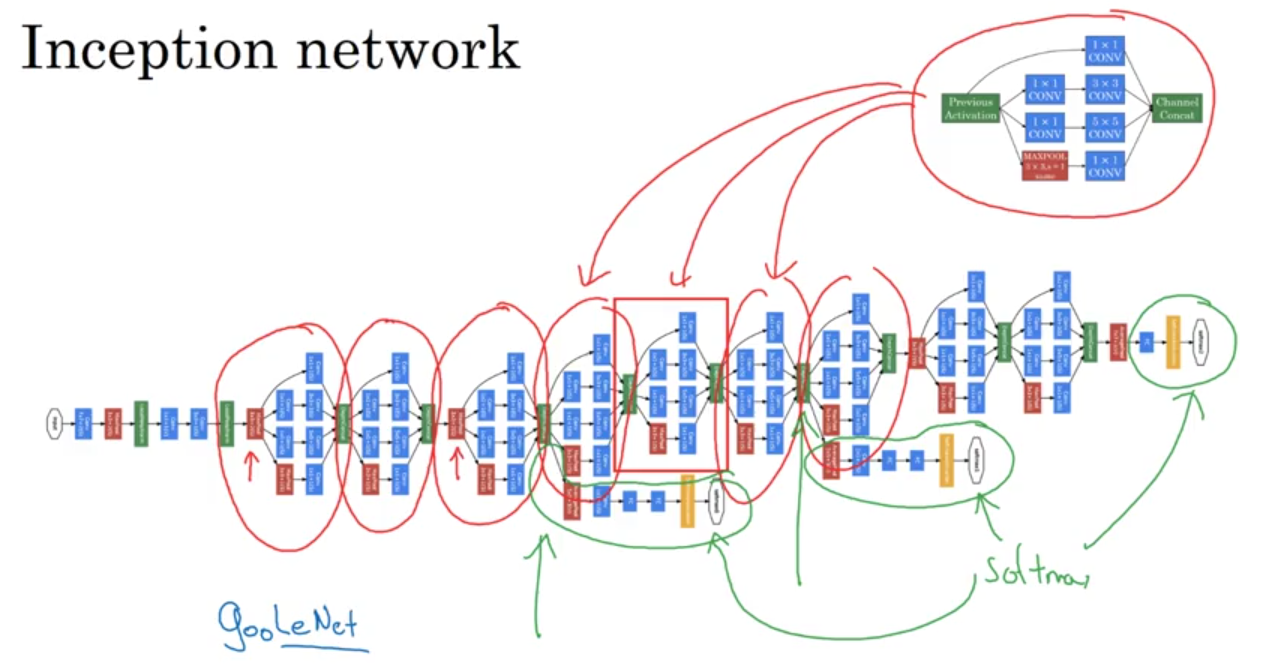
Practical Advices for Using ConvNets
- use architectures of networks published in the literature
- use open source implementations if possible
- use pretrained models and fine-tune on your dataset
Using Open-Source Implementation
- github: open-source code
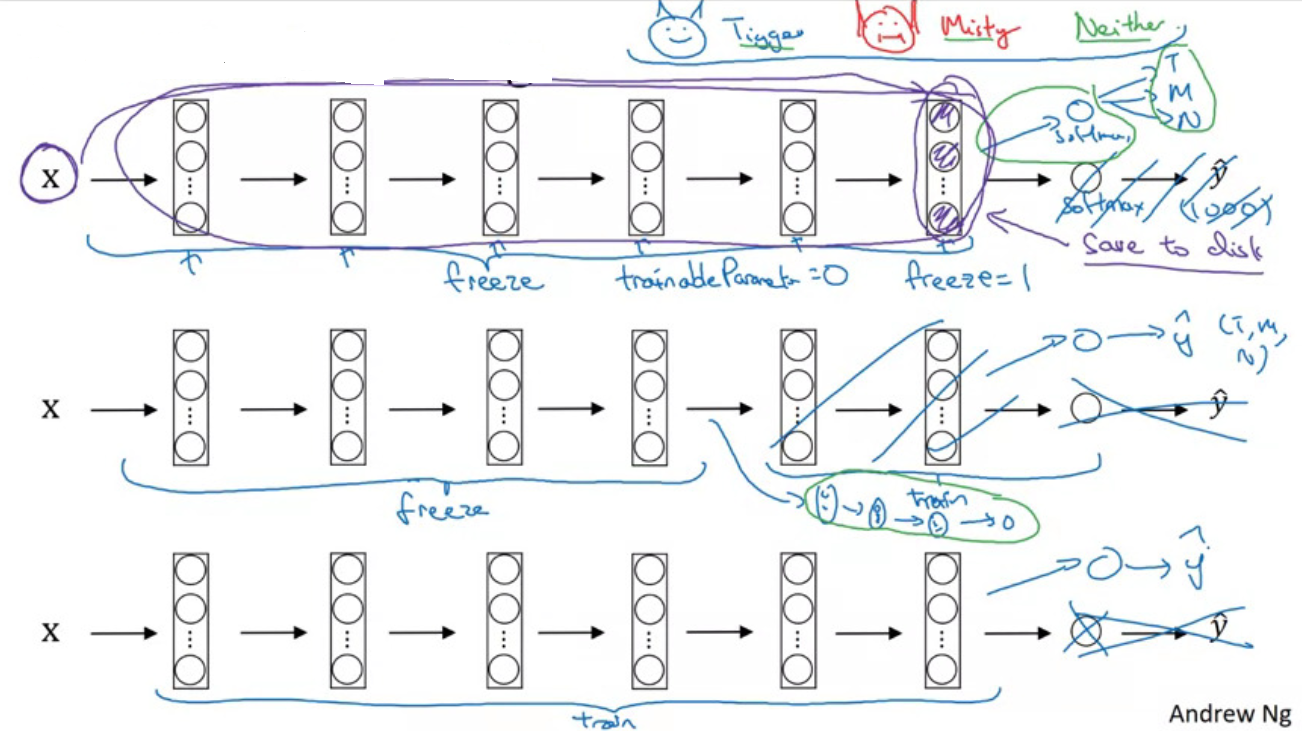
Transfer Learning
open-source weights
small training set:
- train only the softmax layer weights, freeze all of the earlier layers’ weights
- precompute the last activation, save to disk, as input features of a shallow nn
large training set:
- freeze fewer layers, train latter layers or your own network
- open weights as initialization, then train the whole network
Data Augmentation
- mirroring
- random cropping
- rotation
- shearing
- local warping
- color shifting
- advanced: PCA [alexnet paper, PCA color augmentation]
Implementing Distortion During Training
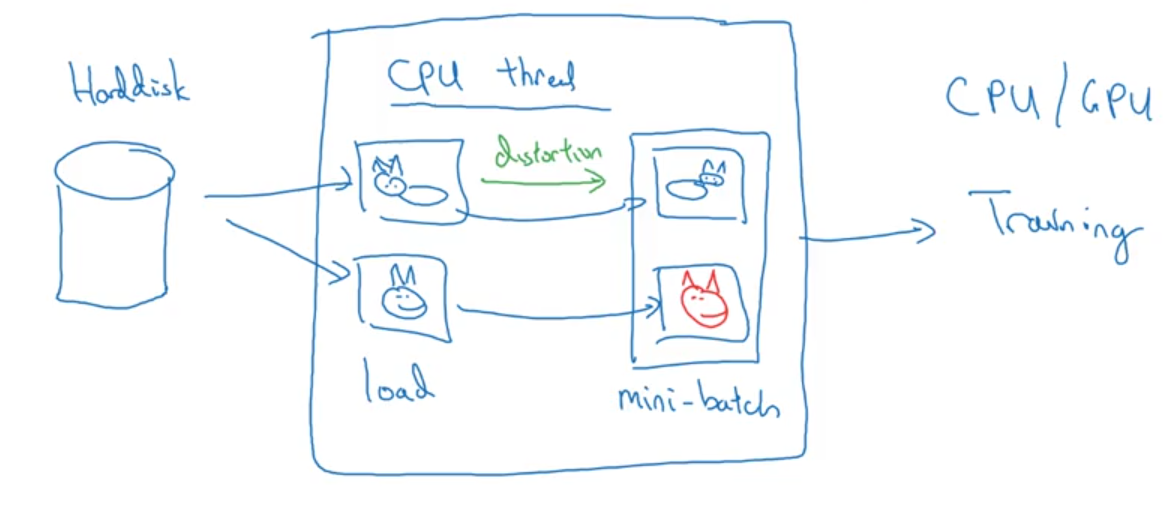
Tips for Doing Well on Benchmarks/Winning Competitions
- Ensembling: train several NNs independently and average their outputs
- Multi-crop at test time:
- run classifier on multiple versions of test images and average results
- e.g. 10-crop

Detection Algorithms
- image classification
- classification with localization
- detection

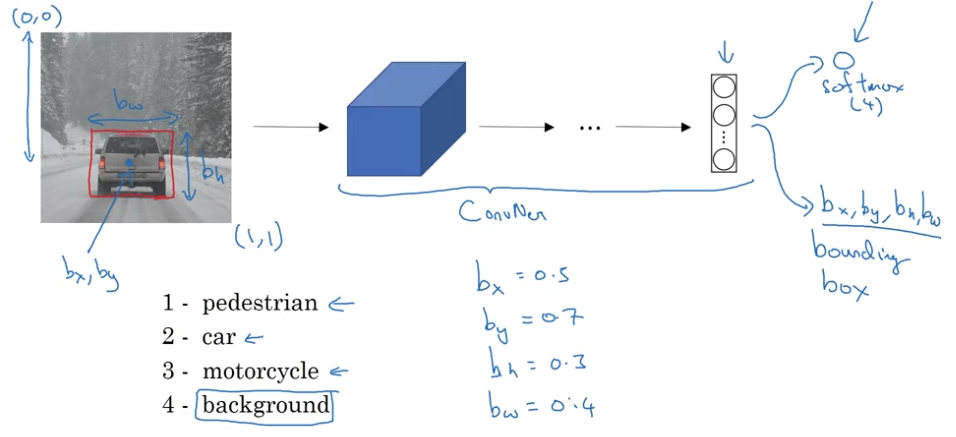
Classification With Localization
- outputs:
- class label
- bounding box
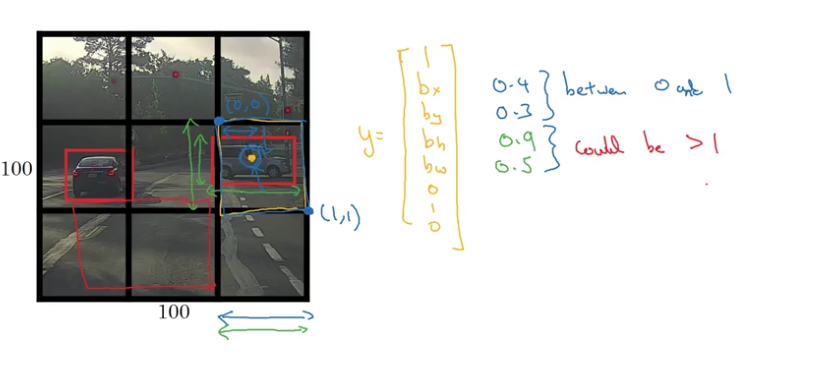
- mid-point
$(b_x,b_y)$ - height:
$b_h$ - weight:
$b_w$
- mid-point
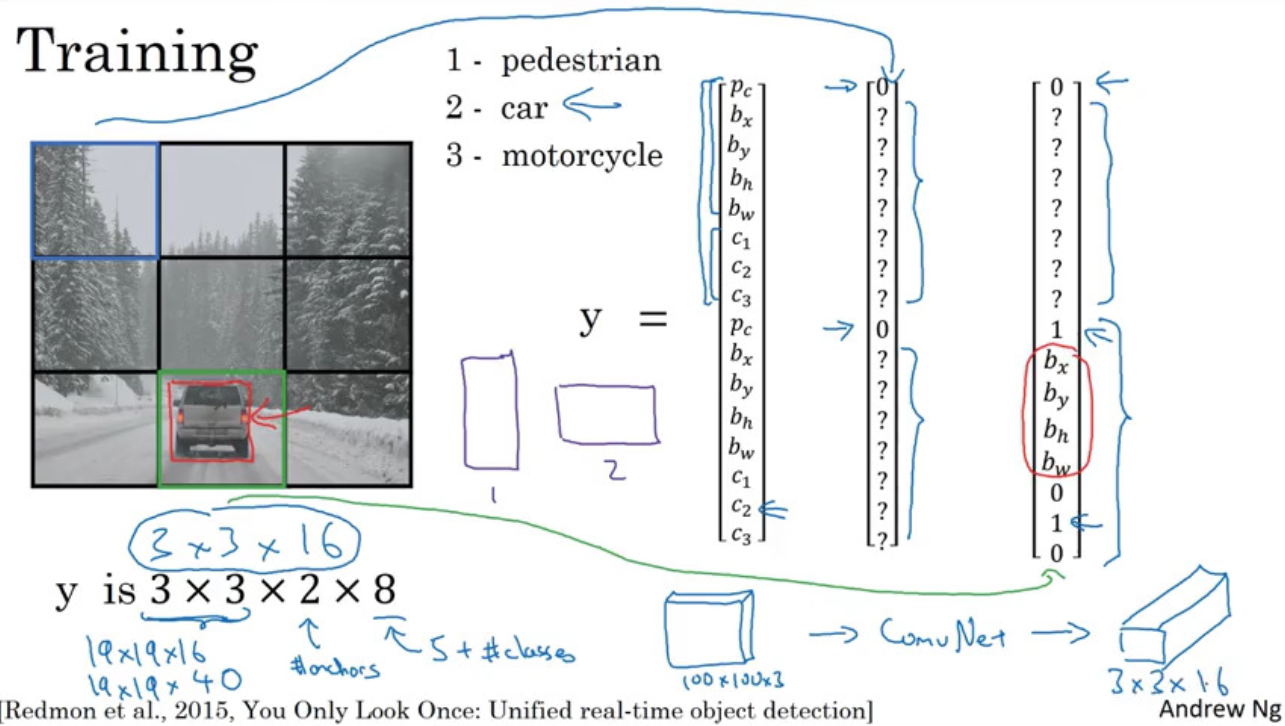
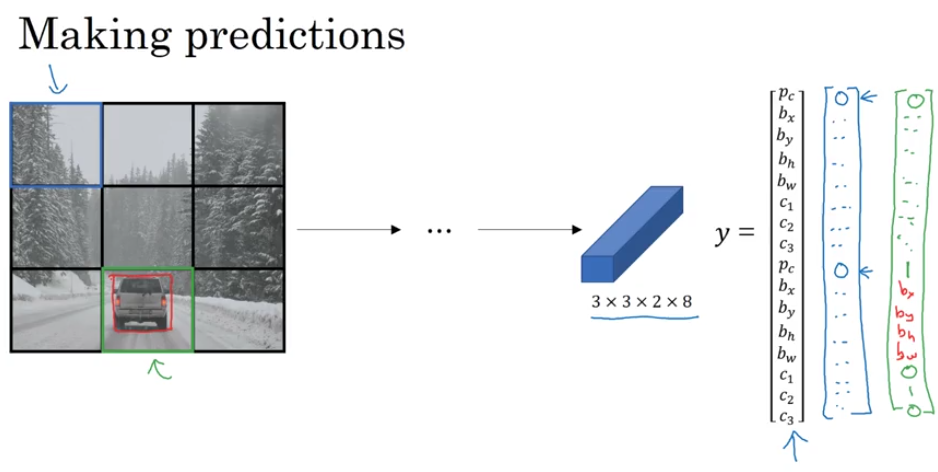
$$ y = \begin{pmatrix} p_c\newline b_x\newline b_y\newline b_h\newline b_w\newline c_1\newline c_2\newline c_3\newline \end{pmatrix},\ p_c=\begin{cases} 1,& \exists\text{ object}\newline 0,&\text{otherwise} \end{cases},\ c_i=\begin{cases} 1,& \exists\text{ object }i\newline 0,&\text{otherwise} \end{cases} $$
- loss function:
$$ \mathcal{L}(\hat{y},y)=\begin{cases} \Vert \hat{y}-y\Vert_2^2, &\text{ if }y_1=1 \newline (\hat{y}_1-y_1)^2, &\text{ if }y_1=0 \end{cases} $$
- in practice, can use
- logistic loss on
$p_c$ - squared error on
$b_.$ - log-likelihood loss on the softmax output of
$c_.$
- logistic loss on
Landmark Detection
- output xy-coordinates of important points
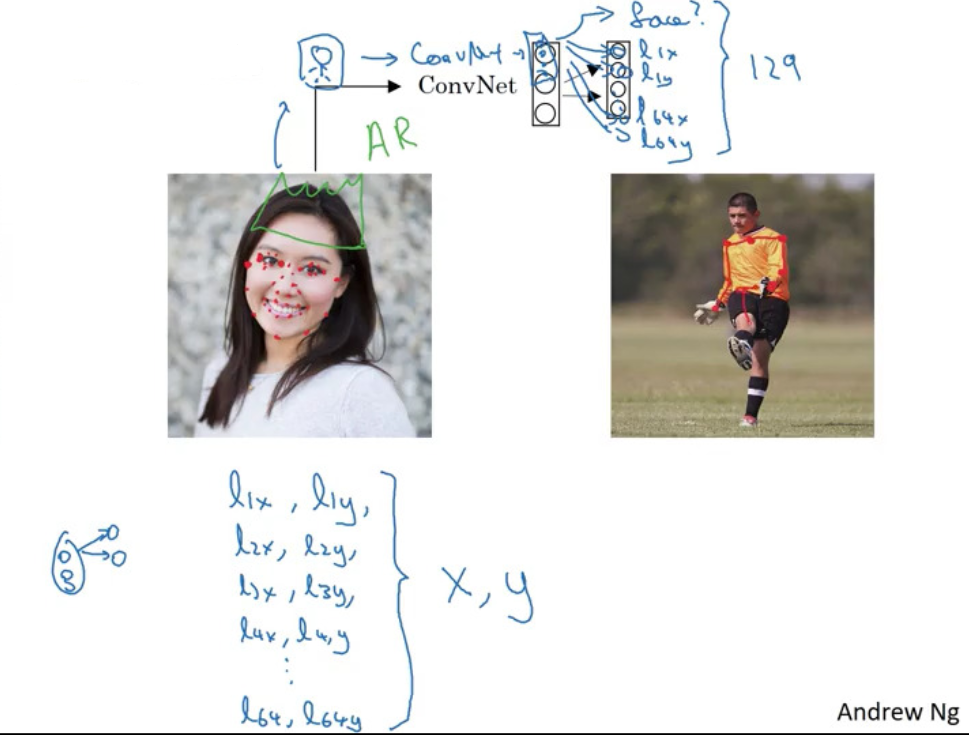
Object Detection
- closely-cropped images
- sliding window detection
- before the rise of nn, use linear classifiers
- if use cnn, computationally expensive
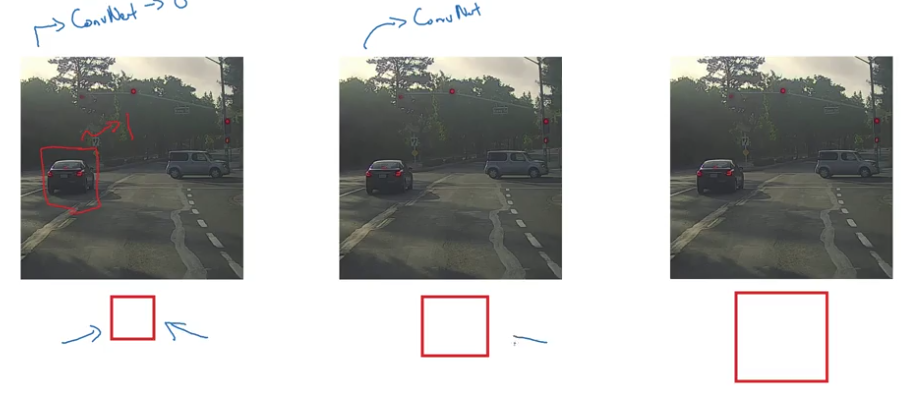
Convolutional Implementation of Sliding Windows
- turning FC layer into convolutional layers
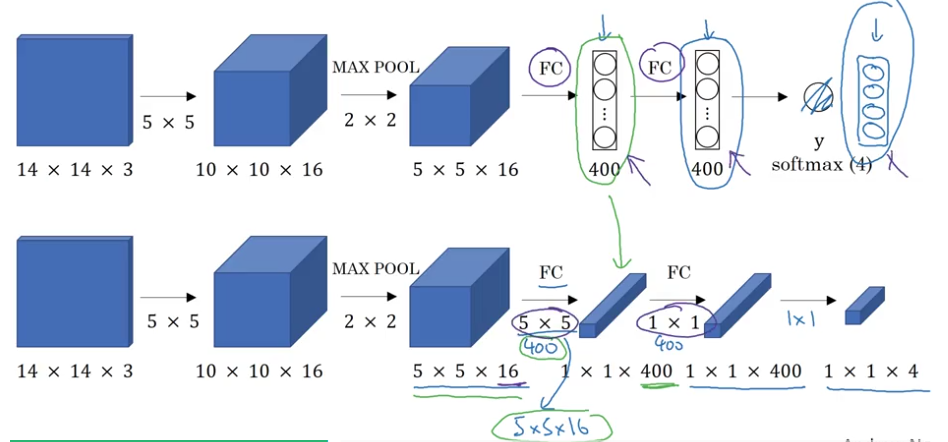
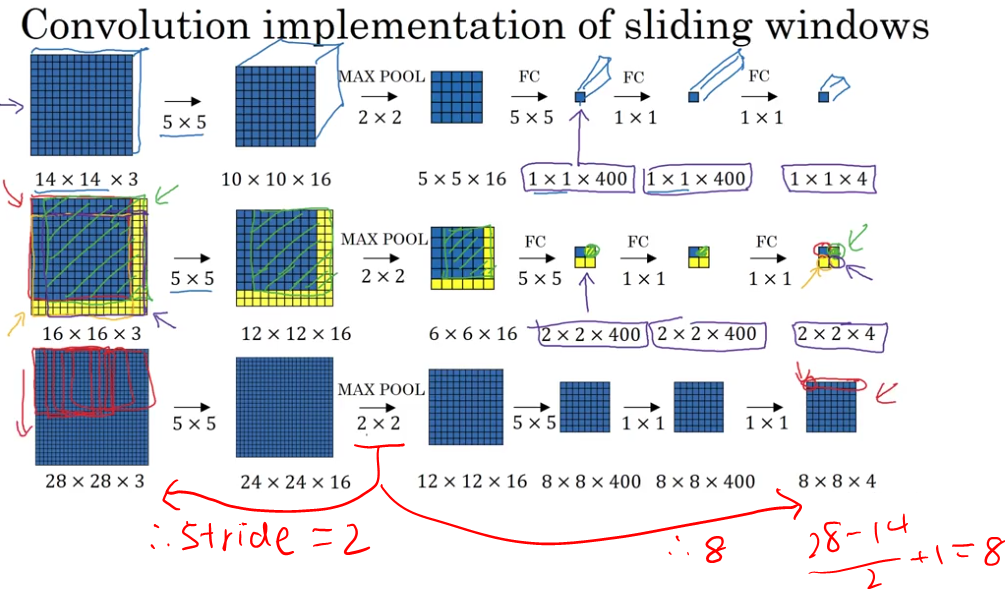
- make all the predictions at the same time
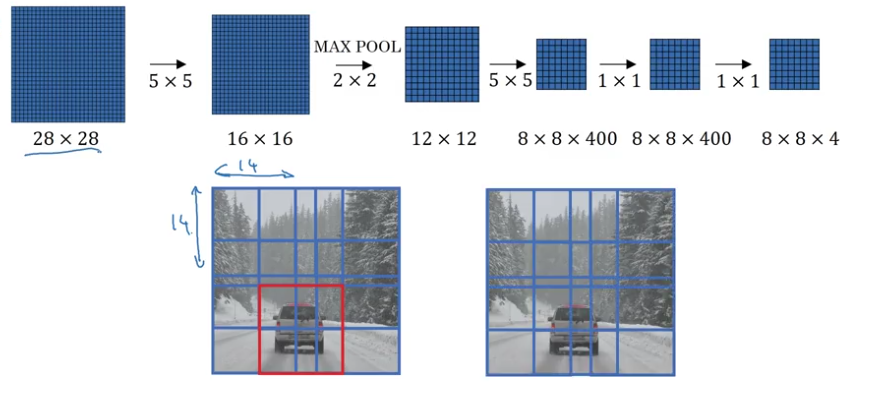
Bounding Box Prediction
how to output accurate bounding box? YOLO algorithm
YOLO = You Only Look Once
convolutional implementation
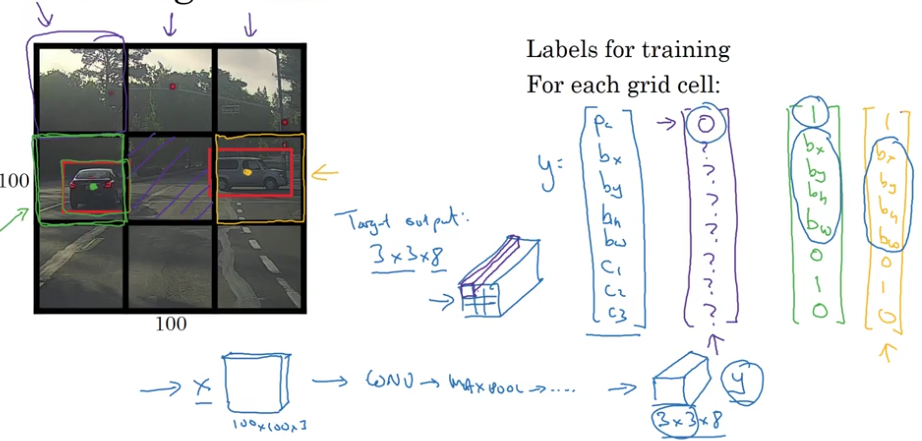
- specify the bounding boxes
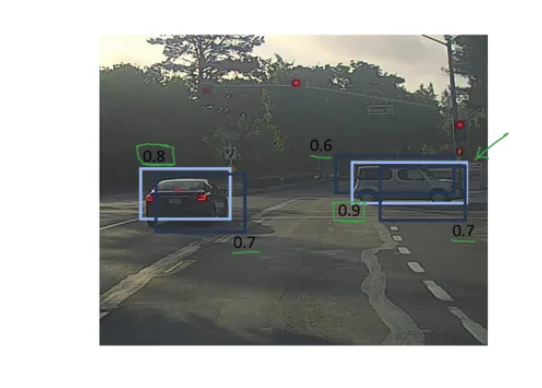
Intersection Over Union (IOU)
- evaluating object localization
$$ \text{“correct” if }IOU = \frac{\text{size of intersection area}}{\text{size of union area}} \geq 0.5 $$

Non-max Suppression
- problem: multiple detection of the same object

Anchor Boxes
- detect overlapping objects

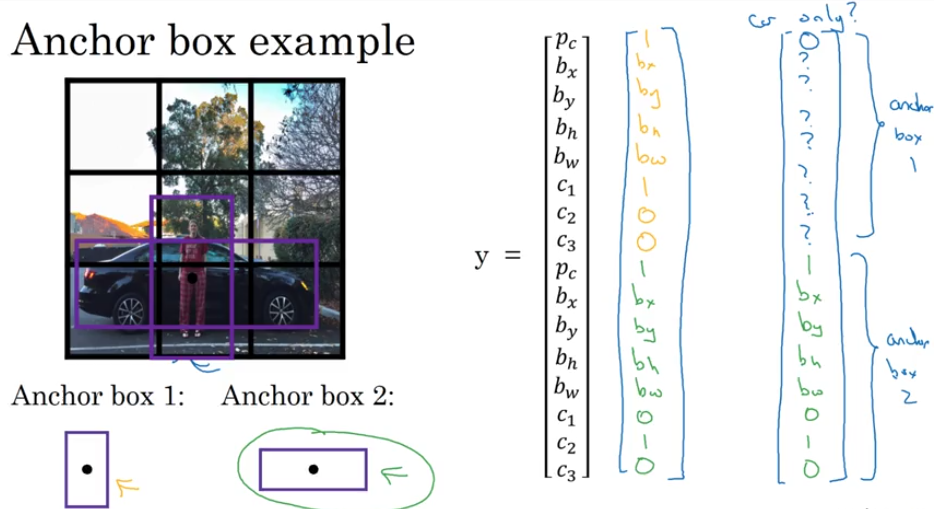
YOLO Algorithm

Region Proposals: R-CNN
- R-CNN:
- propose regions (segmentation algorithm)
- classify proposed regions one at a time, output label + bounding box
- slow
- Fast R-CNN:
- use convolutional implementation of sliding windows to classify all the proposed windows
- Faster R-CNN:
- use convolutional network to propose regions

Face Verification vs Face Recognition
- verification:
- input image, name/ID
- output whether the input image is that of the claimed person
- recognition:
- has a database of
$K$persons - get an input image
- output ID if the image is any of the
$K$persons (or “not recognized”)
- has a database of
One Shot Learning
- learn from one example to recognize the person again
- learn a similarity function:
$d(img1, img2)$= degrees of difference between images- if
$d(img1, img2)\leq \tau$, ‘same’ , otherwise, ‘different’
- how to train the function?
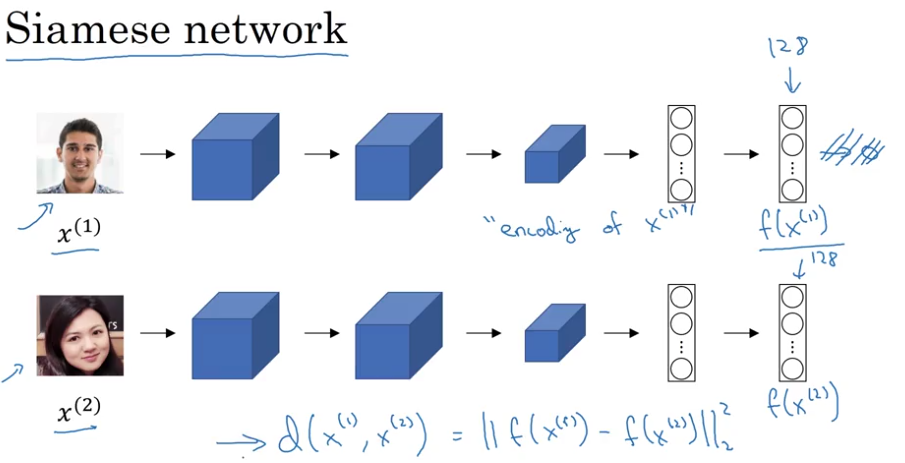
Siamese Network
- output:
$f(\cdot)$, encoding of image example - define
$$ d(x^{(1)}, x^{(2)})=\Vert f(x^{(1)})-f(x^{(2)})\Vert_2^2 $$
- goal of learning:
$\Vert f(x^{(i)})-f(x^{(j)})\Vert_2^2$is small of$x^{(i)},x^{(j)}$are the same person$\Vert f(x^{(i)})-f(x^{(j)})\Vert_2^2$is large of$x^{(i)},x^{(j)}$are different persons
Triplet Loss
- Anchor/Positive/Negative image
- learning objective:
- want
$\Vert f(A)-f(P)\Vert^2\leq \Vert f(A)-f(N)\Vert^2$ - make sure not output trivial encoding
- modification:
$\Vert f(A)-f(P)\Vert^2- \Vert f(A)-f(N)\Vert^2+\alpha\leq 0$ $\alpha$= margin
- want
- loss function: given 3 images
$(A, P, N)$,
$$ \mathcal{L}(A,P,N)=max(\Vert f(A)-f(P)\Vert^2- \Vert f(A)-f(N)\Vert^2+\alpha, 0) $$
- overall cost:
$$ J = \sum_{i=1}^m\mathcal{L}(A^{(i)}, P^{(i)}, N^{(i)}) $$
- training set: 10k pictures of 1k person (multiple pics of the same person)
- choosing the triplets
$A,P,N$:- during training, if
$A,P,N$are randomly chosen,$d(A,P)+\alpha\leq d(A,N)$is easily satisfied - need to choose triplets that are hard to train on
- during training, if
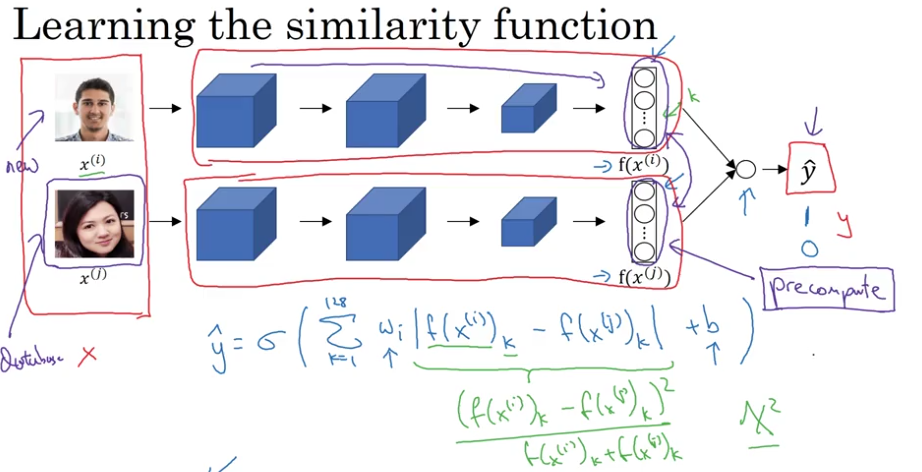
Face Verification and Binary Classification

Neural Style Transfer
- Content/Style/Generated image

What are Deep ConvNets Learning?
- Pick a unit in layer 1. Find the nine image patches that maximize the unit’s activation.
- Repeat for other 9 units.
- Deeper layers will see larger image patches.

Visualizing and understanding convolutional networks
Neural Style Transfer Cost Function
$$ J(G)=\alpha J_{content}(C,G) +\beta J_{style}(S,G) $$
- initiate G randomly
- use gradient descent to minimize
$J(G)$
Content Cost Function
- similarity between C and G
- use pre-trained ConvNet (e.g. VGG network)
- say you use hidden layer
$\ell$to compute cost - let
$a^{[\ell](C)}$and$a^{[\ell](G)}$be the activation of layer$\ell$on the images - if
$a^{[\ell](C)}$and$a^{[\ell](G)}$are similar, both images gave similar content
$$ J_{content}(C,G):=\frac{1}{2}\Vert a^{[\ell](C)}-a^{[\ell] (G)}\Vert^2 $$
Style Cost Function
say you use hidden layer
$\ell$’s activation to measure styledefine style as correlation between activations across channels
style matrix (gram matrix)
$$
a^{[\ell]}_{i,j,k}=\text{activation at }(i,j,k).\\
G_{kk’}^{[\ell]}=\sum_{i=1}^{n_H^{[\ell]}}\sum_{j=1}^{n_W^{[\ell]}} a_{ijk}^{[\ell]}a_{ijk’}^{[\ell]},\ \ k,k’=1,2,\ldots,n_C^{[\ell]}.\\
G^{[\ell]}=(G_{kk’}^{[\ell]})\in\mathbb{R}^{n_C^{[\ell]}\times n_C^{[\ell]}}.
$$
- style matrices for the style image and generated image
$G^{[\ell](S)}, G^{[\ell](G)}$ - style cost
$$ J_{style}^{[\ell]}(S,G)=\frac{1}{(2n_{H}^{[\ell]}n_W^{[\ell]}n_C^{[\ell]})^2}\sum_{k,k’}\Vert G^{[\ell](S)}-G^{[\ell](G)}\Vert^2_F $$
$$ J_{style}(S,G)=\sum_l \lambda^{[\ell]} J_{style}^{[\ell]}(S,G) $$
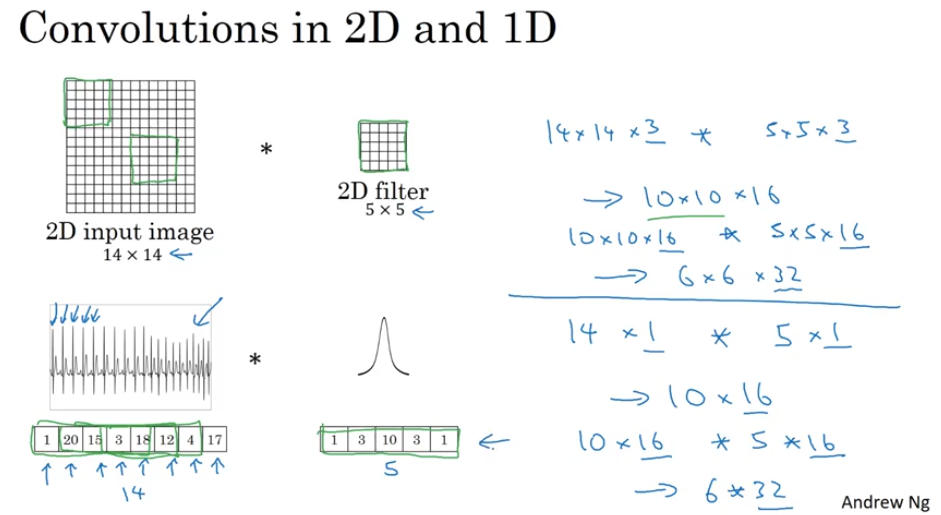
Convolutions in 1D and 3D