Cost Function
Logistic regression $$ \min_{\theta}\frac{1}{N}\sum_{i=1}^N \left[y^{(i)}\left(-\log \frac{1}{1+e^{-\theta^T x^{(i)}}}\right)+(1-y^{(i)})\left(-\log \frac{e^{-\theta^T x^{(i)}}}{1+e^{-\theta^T x^{(i)}}}\right)\right] +\frac{\lambda}{2N}\sum_{j=1}^p\theta_j^2 $$
- if
$y=1$, want$\theta^Tx\gg 0$ - if
$y=0$, want$\theta^Tx\ll 0$
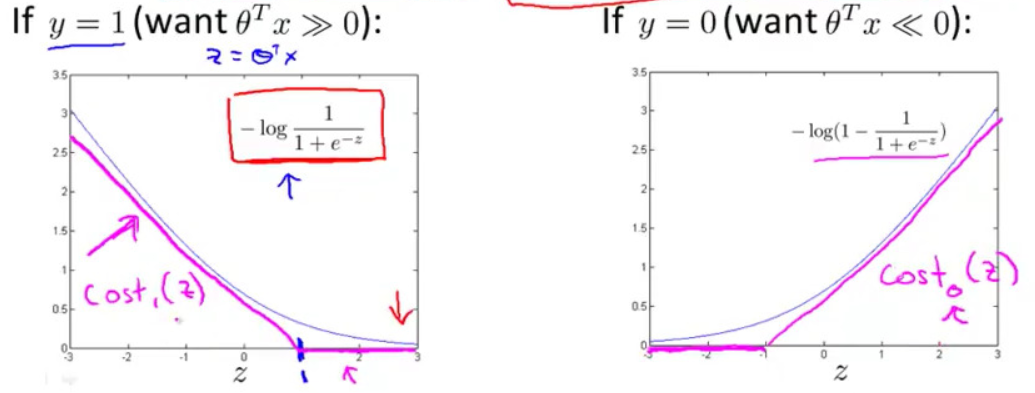
SVM $$ \min_{\theta} C\sum_{i=1}^N \left[y^{(i)}cost_1(\theta^Tx^{(i)}) +(1-y^{(i)})cost_0(\theta^T x^{(i)})\right] +\frac{1}{2}\sum_{j=1}^p\theta_j^2 $$
- if
$y=1$, want$\theta^Tx\geq 1$ - if
$y=0$, want$\theta^Tx\leq -1$
Large Margin Classification
- SVM Decision Boundary
$$
\min_{\theta} \frac{1}{2}\sum_{j=1}^p\theta_j^2\\
s.t. \begin{cases}
\theta^Tx^{(i)}\geq 1 &\text{if } y^{(i)}=1\newline
\theta^Tx^{(i)}\leq -1 &\text{if } y^{(i)}=0\newline
\end{cases}
$$
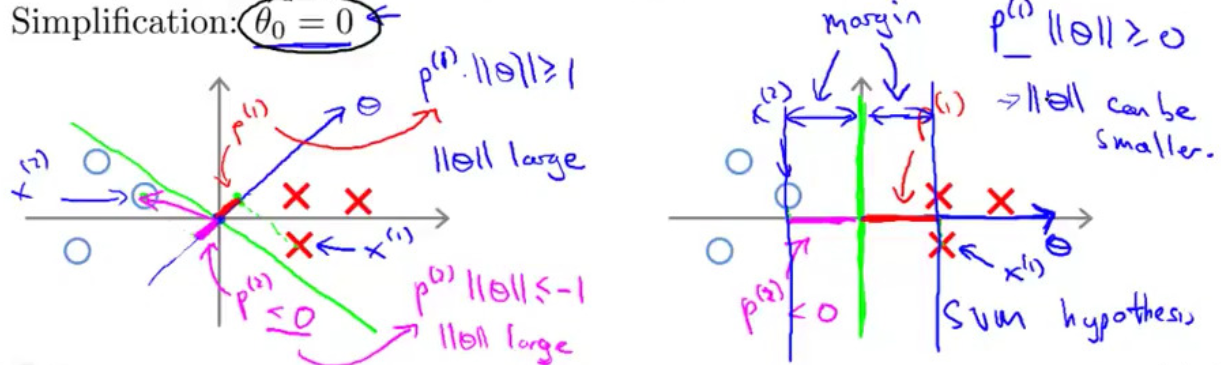
Simplification: $\theta_0=0, p=2$
$$
\min_{\theta} \frac{1}{2}\Vert\theta\Vert_2^2\\
s.t. \begin{cases}
u^{(i)}\Vert\theta\Vert \geq 1 &\text{if } y^{(i)}=1\newline
u^{(i)}\Vert\theta\Vert \leq -1 &\text{if } y^{(i)}=0\newline
\end{cases}
$$
where $u^{(i)}$ is the projection of $x^{(i)}$ onto $\theta$.
Kernels
kernels = similarity functions
Gaussian kernel: landmark
$l^{(k)}$$$ f_k=\text{similarity}(x,l^{(k)})=\exp\left(-\frac{\Vert x-l^{(k)}\Vert^2}{2\sigma^2}\right) $$- if
$x\approx l^{(k)}$,$f_k\approx 1$ - if
$x$is far from$l^{(k)}$,$f_k\approx 0$ - predict 1 when
$\theta^T f\geq 0$
- if
choice of landmarks
- Given
$\{(x^{(i)}, y^{(i)})\}_{i=1}^N$- Choose
$l^{(i)}=x^{(i)}, i=1,2,\ldots,N$- Given example
$x$,$$ f :=\begin{pmatrix} f_0\newline f_1\newline \vdots\newline f_N \end{pmatrix},\ \ \text{where } f_0:=1, f_k :=\text{similarity}(x, l^{(k)})=\text{similarity}(x, x^{(k)}) $$
- hypothesis: given
$x$, compute features$f\in\mathbb{R}^{N+1}$. Predict$y=1$if$\theta^T y\geq 0$.- training:
$$ \min_{\theta}C\sum_{i=1}\left[y^{(i)}cost_1(\theta^T f^{(i)}) + (1-y^{(i)})cost_0(\theta^T f^{(i)})\right]+\frac{1}{2}\sum_{j=1}^N \theta_j^2 $$
- replace
$\sum_{j=1}^N \theta_j^2=\theta^T\theta$(ignore$\theta_0$) with$\theta^TM\theta$(rescale, for efficiency)
Hyperparameters
$C=\frac{1}{\lambda}$
- large
$C$: lower bias, higher variance - small
$C$: higher bias, lower variance
$\sigma^2$
- large
$\sigma^2$: feature$f_i$vary more smoothly, higher bias, lower variance - small
$\sigma^2$: feature$f_i$vary less smoothly, lower bias, higher variance
address overfitting
- decrease
$C$ - increase
$\sigma^2$
SVM in Practice
- use SVM software packages (e.g. liblinear, libsvm) to solve for parameters
$\theta$ - need to specify
- choice of
$C$ - choice of kernel
- no kernel = “linear kernel”, predict
$y=1$if$\theta^Tx\geq 0$ - Gaussian kernel: need to choose
$\sigma^2$, do perform feature scaling beforehand
- no kernel = “linear kernel”, predict
- other choices of kernel: need to satisfy Mercer’s Theorem
- polynomial kernel:
$k(x,l)=(x^Tl + c)^d$ - string kernel
- chi-square kernel
- histogram intersection kernel
- choice of
Multiclass SVM Classification
- one-versus-all
Logistic Regression versus SVMs
- if # of features is large (relative to # of examples): use logistic regression, or SVM without a kernel (linear kernel)
- if # of features is small, # of examples is intermediate: use SVM with Gaussian kernel
- if # of features is small, # of examples is large: add/create more features, then use logistic regression or SVM without a kernel
- neural networks likely to work well for most of these settings, but may be slower to train